Black Belt
Black Belt DeepTrading with Tensorflow IV
After you have trained a neural network (NN), you would want to save it for future calculation and eventually deploying to production. So, what is a Tensorflow model? Tensorflow model contains the network design or graph and values of the network parameters that we have trained.
Important Note: I know that the reader is impatient to use real data from the financial markets. Please be patient, I promise that we will use them properly when you are ready, but now we must strengthen our knowledge to have a strong foundation.
Also, remember to have a look at the first posts of the series to have the full picture:
https://todotrader.com/deeptrading-with-tensorflow/
https://todotrader.com/deeptrading-with-tensorflow-ii/
https://todotrader.com/deeptrading-with-tensorflow-iii/
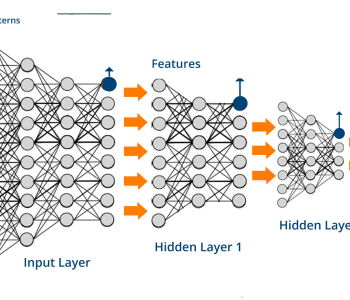
Implementing a one hidden layer Neural Network with save and restore
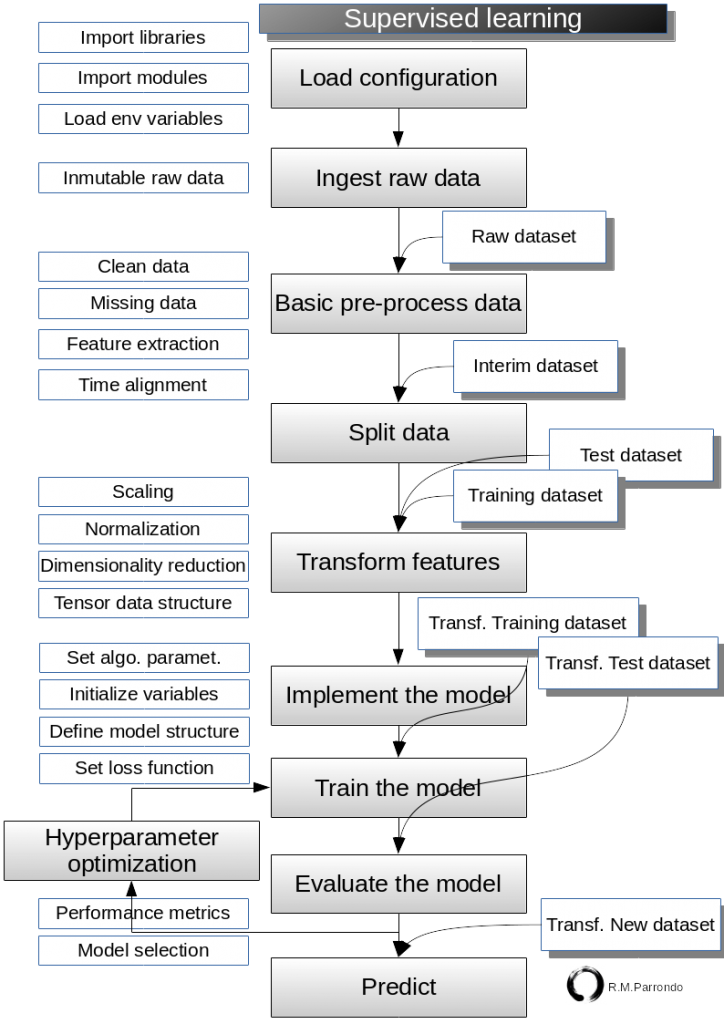
Here is the one-hidden layer network model again to refresh our knowledge. As usual, we will follow our supervised learning flowchart.

The progress of the model can be saved during and after training. This means that a model can be resumed where it left off and avoid long training times. Saving also means that you can share your model and others can recreate your work.
We will illustrate how to create a one hidden layer NN, save it and make predictions with a trained model after reloading it.
Again, we will use the iris data for this exercise. Remember the important note above!
We will build a
There are several differences with respect to the example before in order to il
Caution: TensorFlow model files are code. Be careful with untrusted code. See Using TensorFlow Securely for details.
Load configuration
In [1]:
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.datasets import load_iris
from tensorflow.python.framework import ops
import pandas as pd
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
Ingest raw data
In [2]:
# Before getting into pandas dataframes we will load an example dataset from sklearn library
# type(data) #iris is a bunch instance which is inherited from dictionary
data = load_iris() #load iris dataset
# We get a pandas dataframe to better visualize the datasets
df = pd.DataFrame(data.data, columns=data.feature_names)
X_raw = np.array([x[0:3] for x in data.data])
y_raw = np.array([x[3] for x in data.data])
# Dimensions of dataset
print("Dimensions of dataset")
n = X_raw.shape[0]
p = X_raw.shape[1]
print("n=",n,"p=",p)
Dimensions of dataset
n= 150 p= 3
In [3]:
data.keys() #keys of the dictionary
Out[3]:
dict_keys(['target_names', 'target', 'data', 'DESCR', 'feature_names'])In [4]:
X_raw.shape # Array 150x3. Each element is a 3-dimensional data point: sepal length, sepal width, petal length
Out[4]:
(150, 3)In [5]:
y_raw.shape # Vector 150. Each element is a 1-dimensional (scalar) data point: petal width
Out[5]:
(150,)In [6]:
df
Out[6]:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 |
| 6 | 4.6 | 3.4 | 1.4 | 0.3 |
| 7 | 5.0 | 3.4 | 1.5 | 0.2 |
| 8 | 4.4 | 2.9 | 1.4 | 0.2 |
| 9 | 4.9 | 3.1 | 1.5 | 0.1 |
| 10 | 5.4 | 3.7 | 1.5 | 0.2 |
| 11 | 4.8 | 3.4 | 1.6 | 0.2 |
| 12 | 4.8 | 3.0 | 1.4 | 0.1 |
| 13 | 4.3 | 3.0 | 1.1 | 0.1 |
| 14 | 5.8 | 4.0 | 1.2 | 0.2 |
| 15 | 5.7 | 4.4 | 1.5 | 0.4 |
| 16 | 5.4 | 3.9 | 1.3 | 0.4 |
| 17 | 5.1 | 3.5 | 1.4 | 0.3 |
| 18 | 5.7 | 3.8 | 1.7 | 0.3 |
| 19 | 5.1 | 3.8 | 1.5 | 0.3 |
| 20 | 5.4 | 3.4 | 1.7 | 0.2 |
| 21 | 5.1 | 3.7 | 1.5 | 0.4 |
| 22 | 4.6 | 3.6 | 1.0 | 0.2 |
| 23 | 5.1 | 3.3 | 1.7 | 0.5 |
| 24 | 4.8 | 3.4 | 1.9 | 0.2 |
| 25 | 5.0 | 3.0 | 1.6 | 0.2 |
| 26 | 5.0 | 3.4 | 1.6 | 0.4 |
| 27 | 5.2 | 3.5 | 1.5 | 0.2 |
| 28 | 5.2 | 3.4 | 1.4 | 0.2 |
| 29 | 4.7 | 3.2 | 1.6 | 0.2 |
| … | … | … | … | … |
| 120 | 6.9 | 3.2 | 5.7 | 2.3 |
| 121 | 5.6 | 2.8 | 4.9 | 2.0 |
| 122 | 7.7 | 2.8 | 6.7 | 2.0 |
| 123 | 6.3 | 2.7 | 4.9 | 1.8 |
| 124 | 6.7 | 3.3 | 5.7 | 2.1 |
| 125 | 7.2 | 3.2 | 6.0 | 1.8 |
| 126 | 6.2 | 2.8 | 4.8 | 1.8 |
| 127 | 6.1 | 3.0 | 4.9 | 1.8 |
| 128 | 6.4 | 2.8 | 5.6 | 2.1 |
| 129 | 7.2 | 3.0 | 5.8 | 1.6 |
| 130 | 7.4 | 2.8 | 6.1 | 1.9 |
| 131 | 7.9 | 3.8 | 6.4 | 2.0 |
| 132 | 6.4 | 2.8 | 5.6 | 2.2 |
| 133 | 6.3 | 2.8 | 5.1 | 1.5 |
| 134 | 6.1 | 2.6 | 5.6 | 1.4 |
| 135 | 7.7 | 3.0 | 6.1 | 2.3 |
| 136 | 6.3 | 3.4 | 5.6 | 2.4 |
| 137 | 6.4 | 3.1 | 5.5 | 1.8 |
| 138 | 6.0 | 3.0 | 4.8 | 1.8 |
| 139 | 6.9 | 3.1 | 5.4 | 2.1 |
| 140 | 6.7 | 3.1 | 5.6 | 2.4 |
| 141 | 6.9 | 3.1 | 5.1 | 2.3 |
| 142 | 5.8 | 2.7 | 5.1 | 1.9 |
| 143 | 6.8 | 3.2 | 5.9 | 2.3 |
| 144 | 6.7 | 3.3 | 5.7 | 2.5 |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
Basic pre-process data
In [7]:
#
# Leave in blanck intentionally
#
Split data
In [8]:
# split into train and test sets
# Total samples
nsamples = n
# Splitting into train (70%) and test (30%) sets
split = 70 # training split% ; test (100-split)%
jindex = nsamples*split//100 # Index for slicing the samples
# Samples in train
nsamples_train = jindex
# Samples in test
nsamples_test = nsamples - nsamples_train
print("Total number of samples: ",nsamples,"\nSamples in train set: ", nsamples_train,
"\nSamples in test set: ",nsamples_test)
# Here are train and test samples
X_train = X_raw[:jindex, :]
y_train = y_raw[:jindex]
X_test = X_raw[jindex:, :]
y_test = y_raw[jindex:]
print("X_train.shape = ", X_train.shape, "y_train.shape =", y_train.shape, "\nX_test.shape = ",
X_test.shape, "y_test.shape = ", y_test.shape)
Total number of samples: 150
Samples in train set: 105
Samples in test set: 45
X_train.shape = (105, 3) y_train.shape = (105,)
X_test.shape = (45, 3) y_test.shape = (45,)
Transform features
Note
Be careful do not to write X_test_std = sc.fit_transform(X_test) instead of X_test_std = sc.transform(X_test). In this case, it wouldn’t make a great difference since the mean and standard deviation of the test set should be (quite) similar to the training set. However, this is not always the case in Forex market data, as has been well established in the literature. The correct way is to re-use parameters from the training set if we are doing any kind of transformation. So, the test set should basically stand for “new, unseen” data. In [9]:
# Scale data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
y_train_std = sc.fit_transform(y_train.reshape(-1, 1))
y_test_std = sc.transform(y_test.reshape(-1, 1))
Implement the model
In [10]:
# Clears the default graph stack and resets the global default graph
ops.reset_default_graph()
In [11]:
# make results reproducible
seed = 2
tf.set_random_seed(seed)
np.random.seed(seed)
# Parameters
learning_rate = 0.005
batch_size = 50
n_features = X_train.shape[1]# Number of features in training data
epochs = 1000
display_step = 50
model_path = "/tmp/model.ckpt"
n_classes = 1
# Network Parameters
# See figure of the model
d0 = D = n_features # Layer 0 (Input layer number of features)
d1 = 10 # Layer 1 (1st hidden layer number of features. Selected 10 for this example)
d2 = C = 1 # Layer 2 (Output layer)
# tf Graph input
print("Placeholders")
X = tf.placeholder(dtype=tf.float32, shape=[None, n_features], name="X")
y = tf.placeholder(dtype=tf.float32, shape=[None,n_classes], name="y")
# Initializers
print("Initializers")
sigma = 1
weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=sigma)
bias_initializer = tf.zeros_initializer()
# Create model
def onelayer_perceptron(X, variables):
# Hidden layer with ReLU activation
layer_1 = tf.nn.relu(tf.add(tf.matmul(X, variables['W1']), variables['bias1']))
# Output layer with ReLU activation
out_layer = tf.nn.relu(tf.add(tf.matmul(layer_1, variables['W2']), variables['bias2']))
return out_layer
# Store layers weight & bias
variables = {
'W1': tf.Variable(weight_initializer([n_features, d1]), name="W1"), # inputs -> hidden neurons
'bias1': tf.Variable(bias_initializer([d1]), name="bias1"), # one biases for each hidden neurons
'W2': tf.Variable(weight_initializer([d1, d2]), name="W2"), # hidden inputs -> 1 output
'bias2': tf.Variable(bias_initializer([d2]), name="bias2") # 1 bias for the output
}
# Construct model
y_hat = onelayer_perceptron(X, variables)
# Define loss and optimizer
loss = tf.reduce_mean(tf.square(y - y_hat)) # MSE
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) # Train step
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# 'Saver' op to save and restore all the variables
saver = tf.train.Saver()
Placeholders
Initializers
Train the model and Evaluate the model
In [12]:
# Running first session
print("Starting 1st session...")
with tf.Session() as sess:
# Writer to record image, scalar, histogram and graph for display in tensorboard
writer = tf.summary.FileWriter("/tmp/tensorflow_logs", sess.graph) # create writer
writer.add_graph(sess.graph)
# Run the initializer
sess.run(init)
# Training cycle
train_loss = []
test_loss = []
for epoch in range(epochs):
rand_index = np.random.choice(len(X_train), size=batch_size)
X_rand = X_train[rand_index]
y_rand = np.transpose([y_train[rand_index]])
sess.run(optimizer, feed_dict={X: X_rand, y: y_rand})
train_temp_loss = sess.run(loss, feed_dict={X: X_rand, y: y_rand})
train_loss.append(np.sqrt(train_temp_loss))
test_temp_loss = sess.run(loss, feed_dict={X: X_test, y: np.transpose([y_test])})
test_loss.append(np.sqrt(test_temp_loss))
if (epoch+1) % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "Lost=", \
"{:.9f}".format(train_temp_loss))
# Close writer
writer.flush()
writer.close()
# Save model weights to disk
save_path = saver.save(sess, model_path)
print("Model saved in file: %s" % save_path)
print("First Optimization Finished!")
Starting 1st session...
Epoch: 0050 Lost= 0.599382699
Epoch: 0100 Lost= 0.200652853
Epoch: 0150 Lost= 0.082070500
Epoch: 0200 Lost= 0.046969157
Epoch: 0250 Lost= 0.033277217
Epoch: 0300 Lost= 0.029509921
Epoch: 0350 Lost= 0.046582703
Epoch: 0400 Lost= 0.051407199
Epoch: 0450 Lost= 0.080046408
Epoch: 0500 Lost= 0.032044422
Epoch: 0550 Lost= 0.028484538
Epoch: 0600 Lost= 0.030885572
Epoch: 0650 Lost= 0.053837571
Epoch: 0700 Lost= 0.030355027
Epoch: 0750 Lost= 0.030203044
Epoch: 0800 Lost= 0.021480566
Epoch: 0850 Lost= 0.011752291
Epoch: 0900 Lost= 0.040840883
Epoch: 0950 Lost= 0.035907771
Epoch: 1000 Lost= 0.042663313
Model saved in file: /tmp/model.ckpt
First Optimization Finished!
In [13]:
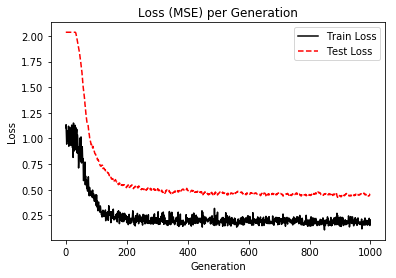
%matplotlib inline
# Plot loss (MSE) over time
plt.plot(train_loss, 'k-', label='Train Loss')
plt.plot(test_loss, 'r--', label='Test Loss')
plt.title('Loss (MSE) per Generation')
plt.legend(loc='upper right')
plt.xlabel('Generation')
plt.ylabel('Loss')
plt.show()

Tensorboard Graph
What follows is the graph we have executed and all t

Saving a Tensorflow model
So, now we have our model saved.
Tensorflow model has four main files:
- Meta graph: This is a protocol buffer which saves the complete Tensorflow graph; i.e. all variables, operations, collections, etc. This file has a .meta extension.
- Two Checkpoint files: they are binary files which contain all the values of the weights, biases, gradients and all the other variables saved. Tensorflow has changed from version 0.11. Instead of a single .ckpt file, we have now two files: .index and .data file that contains our training variables.
- Along with thes, Tensorflow also has a file named checkpoint which simply keeps a record of latest checkpoint files saved.
Retrain the model
We can retrain the model as many times as we want to.
In [14]:
# Running a new session
print("Starting 2nd session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
# Restore model weights from previously saved model
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# Resume training
for epoch in range(epochs*2):
rand_index = np.random.choice(len(X_train), size=batch_size)
X_rand = X_train[rand_index]
y_rand = np.transpose([y_train[rand_index]])
sess.run(optimizer, feed_dict={X: X_rand, y: y_rand})
train_temp_loss = sess.run(loss, feed_dict={X: X_rand, y: y_rand})
train_loss.append(np.sqrt(train_temp_loss))
test_temp_loss = sess.run(loss, feed_dict={X: X_test, y: np.transpose([y_test])})
test_loss.append(np.sqrt(test_temp_loss))
if (epoch+1) % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "Lost=", \
"{:.9f}".format(train_temp_loss))
# Close writer
writer.flush()
writer.close()
# Save model weights to disk
save_path = saver.save(sess, model_path)
print("Model saved in file: %s" % save_path)
print("Second Optimization Finished!")
Starting 2nd session...
INFO:tensorflow:Restoring parameters from /tmp/model.ckpt
Model restored from file: /tmp/model.ckpt
Epoch: 0050 Lost= 0.045188859
Epoch: 0100 Lost= 0.035137746
Epoch: 0150 Lost= 0.040114976
Epoch: 0200 Lost= 0.040839382
Epoch: 0250 Lost= 0.029388864
Epoch: 0300 Lost= 0.050860386
Epoch: 0350 Lost= 0.023227667
Epoch: 0400 Lost= 0.034531657
Epoch: 0450 Lost= 0.036823772
Epoch: 0500 Lost= 0.020957258
Epoch: 0550 Lost= 0.023199901
Epoch: 0600 Lost= 0.029416963
Epoch: 0650 Lost= 0.028286777
Epoch: 0700 Lost= 0.029708408
Epoch: 0750 Lost= 0.038849130
Epoch: 0800 Lost= 0.021901334
Epoch: 0850 Lost= 0.019867409
Epoch: 0900 Lost= 0.038035385
Epoch: 0950 Lost= 0.046836123
Epoch: 1000 Lost= 0.024480129
Epoch: 1050 Lost= 0.025052661
Epoch: 1100 Lost= 0.028433315
Epoch: 1150 Lost= 0.022785973
Epoch: 1200 Lost= 0.018632039
Epoch: 1250 Lost= 0.024766553
Epoch: 1300 Lost= 0.027888060
Epoch: 1350 Lost= 0.030560365
Epoch: 1400 Lost= 0.041359652
Epoch: 1450 Lost= 0.015819877
Epoch: 1500 Lost= 0.029382044
Epoch: 1550 Lost= 0.034098670
Epoch: 1600 Lost= 0.025412932
Epoch: 1650 Lost= 0.036478702
Epoch: 1700 Lost= 0.030148495
Epoch: 1750 Lost= 0.016189585
Epoch: 1800 Lost= 0.023110745
Epoch: 1850 Lost= 0.029191718
Epoch: 1900 Lost= 0.018225947
Epoch: 1950 Lost= 0.023598077
Epoch: 2000 Lost= 0.015231807
Model saved in file: /tmp/model.ckpt
Second Optimization Finished!
Predict
We got it!
Finally, we can use the model to make some predictions.
In [15]:
# Running a new session for predictions
print("Starting prediction session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
# Restore model weights from previously saved model
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# We try to predict the petal width (cm) of three samples
#Caution!!! This data are not the right data (see below why)
feed_dict = {X: [[5.1, 3.5, 1.4],
[4.8, 3.0, 1.4],
[6.3, 3.4, 5.6]]
}
prediction = sess.run(y_hat, feed_dict)
print(prediction) # True value 0.2, 0.1, 2.4
Starting prediction session...
INFO:tensorflow:Restoring parameters from /tmp/model.ckpt
Model restored from file: /tmp/model.ckpt
[[0.19734718]
[0.28260154]
[1.7156498 ]]
Caution Note: continue reading
OK, not very good results. But it is worst that we could think! Data are not right because we have trained our model with transformed data (standardization) and now we must use again transformed data to make predictions. Also, we will get back-transformed data again. So, we must inverse the transformation to get the original kind of data.
First: transform our original data. The data we want to make the prediction about.
In [16]:
X_pred = [[5.1, 3.5, 1.4],
[4.8, 3.0, 1.4],
[6.3, 3.4, 5.6]]
In [17]:
X_pred_std = sc.transform(X_pred)
X_pred_std
Out[17]:
array([[6.86549436, 4.28228483, 0.89182234],
[6.38114257, 3.47503186, 0.89182234],
[8.8029015 , 4.12083424, 7.67274733]])Second: we are ready to make the predictions
In [18]:
# Running a new session for predictions
print("Starting prediction session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
# Restore model weights from previously saved model
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# We try to predict the petal width (cm) of three samples
feed_dict_std = {X: [[6.86549436, 4.28228483, 0.89182234],
[6.38114257, 3.47503186, 0.89182234],
[8.8029015 , 4.12083424, 7.67274733]]}
prediction = sess.run(y_hat, feed_dict_std)
print(prediction) # True value 0.2, 0.1, 2.4
Starting prediction session...
INFO:tensorflow:Restoring parameters from /tmp/model.ckpt
Model restored from file: /tmp/model.ckpt
[[0.15292837]
[0.20799588]
[2.3737454 ]]
Third: we reverse the transformation
In [19]:
y_hat_rev = sc.inverse_transform(prediction)
y_hat_rev
Out[19]:
array([[0.9423405],
[0.9764485],
[2.3178802]], dtype=float32)Not bad. True values are 0.2, 0.1, 2.4. We’ll try to improve them with a deeper network. That is the goal of the next notebook.
In the mean time, try to have a full comprehension of this result.
Remember you can get the full Jupyter notebook on my Github repo: