Black Belt
Black Belt Deep Trading with TensorFlow: Recapitulating
We have already traveled a good part of the trip, but there is still an important part. In this post, I tell you where we are and how much we have left.
Courage, we sure got it!
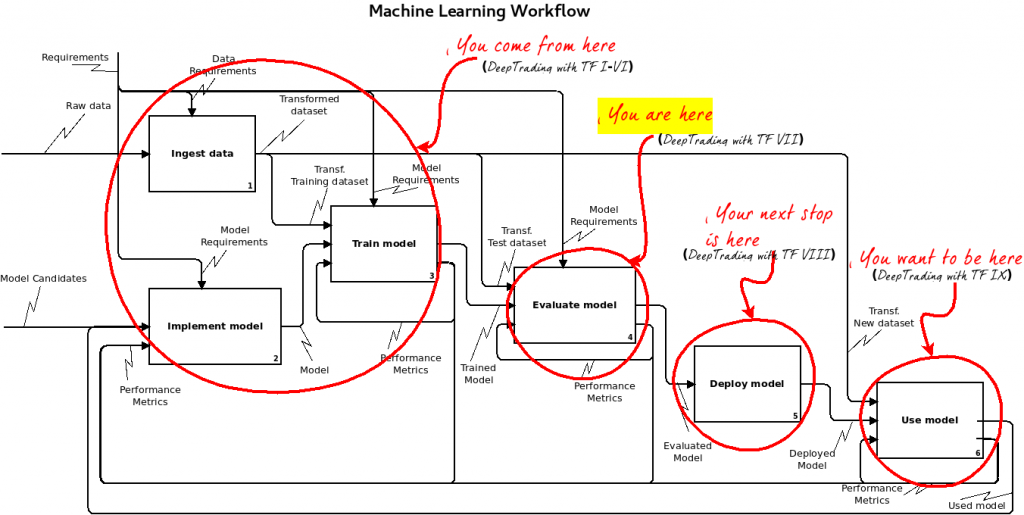
The Machine Learning Workflow
The following diagram provides a high-level overview of the stages in a machine learning workflow.
It is made in the IDEF0 style because I am looking for simplicity (BPMN is not pleasant for what I want to express here).
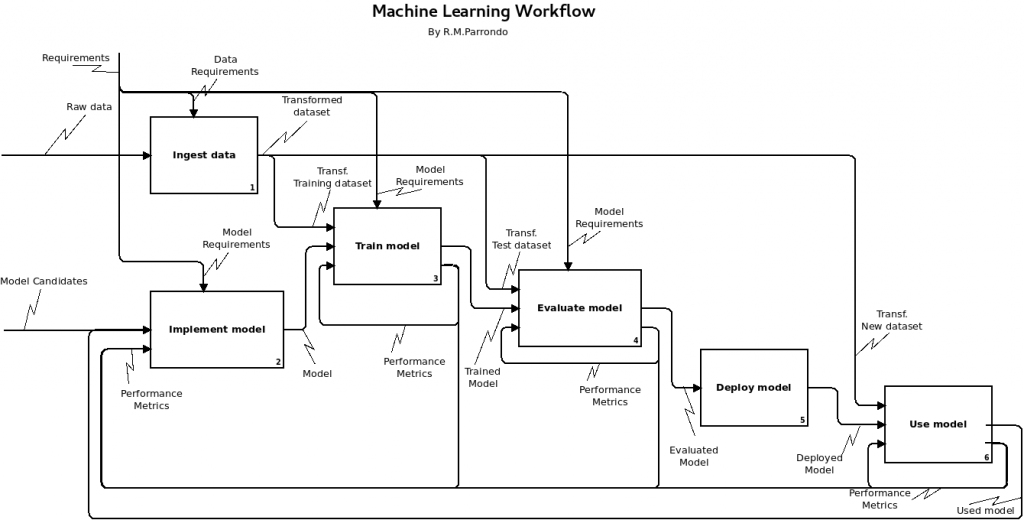
In order to develop and manage a model ready for production in trading, you must work through the following stages:
- Ingest data (Get and prepare your data.)
- Implement the model (Develop your model.)
- Train a machine learning model with your data:
- Train the model
- Evaluate the accuracy of the model
- Adjust the hyper-parameters (with performance metrics)
- Deploy your trained model.
- Use the model (Send prediction requests to your model):
- Online prediction
- Batch Prediction
- Monitor the predictions continuously.
- Manage your models and their versions.
These stages are iterative. You may need to reevaluate and return to an earlier step at any point in the process.
Before you begin, evaluate the problem
Before you start thinking about how to solve a problem with machine learning, take some time to analyze the trading problem you are trying to solve. Ask yourself the following questions:
Do you have a well defined trading problem to solve?
Many different approaches are possible when machine learning is used to recognize patterns in the data. It is es
Is machine learning the best solution for your problem?
Supervised machine learning (the style of machine learning described in this series of posts) adapts well to certain types of problems.
You should only consider using the ML in order to solve your problem if you have access to a considerable set of data to train your model. There are no absolutes about how much information is sufficient. Each feature (data attribute) that you include in your model increases the number of instances (data records) you need to properly train the model. Consult the recommendations of the ML for guidance in the relevant bibliography.
You should also take into account the division of the data set into three subsets: one for the training, another for the evaluation (or validation) and another for the test.
Research alternatives that can provide a more natural and more concrete way to solve the problem. For example, if all you are looking for is rebalancing a portfolio (there is a wide variety of techniques available)
How can you measure if the model is correct?
One of the biggest challenges of creating an ML model is knowing when you have completed the model development phase. It is tempting to continue to define the model better for longer, which draws more and more small improvements in precision. You should know what it means to complete correctly before starting the process. Consider the level of accuracy sufficient for your needs. Consider the consequences of the corresponding error level. Think that improving a few tenths of pips is undoubtedly an illusion.
Get and prepare your data
You must have access to a broad set of training data that includes the attribute (called a feature in Machine Learning) that you want to be able to infer (predict) according to the other functions. There is a great variety of financial data sources. Look for them!
Basic pre-process data
Once you get your data, you must analyze, understand and prepare them to be the entrance to the training process. Try to perform the following steps:
- Join data from multiple sources and rationalize them in a data set.
- Time alignment of data.
- Visualize the data to look for trends.
- Use data-centric languages and tools to find patterns in the data.
- Identify features in your data. Features include the subset of data attributes you use in your model.
- Clean the data to find anomalous values caused by errors in the input or measurement of data.
Transform features
In the preprocessing step, transform valid and clean data into the format that best suits the needs of your model. Here are some examples of feature transformation:
- Categorical Encoding. Label encoding converts categorical variables to numerical representation which is machine-readable.
- Handling of Skewed data. Statistical techniques often assume the normality of distributions. When you use regression algorithms such as linear regression or neural networks, you are likely to see great improvements if you transform the variables with asymmetric distributions. Financial time series are skewed.
- Apply formatting rules to the data. For example, if you remove the HTML tagging of a text feature.
- Reduce data redundancy through simplification. For example, convert a text feature into a word bag representation.
- Represent the text numerically. For example, when you assign values to each possible value in a categorical characteristic.
- As
s igning key values to data. - Scaling. It is a method of transforming data into a particular range. There are several scaling methods.
- Dummy Variables. You need to convert any non-numerical values to integers or floats to utilize them in most machine learning libraries. For low cardinality variables, the best method is usually to turn the feature into one column per unique value, with a “0” where the value is not present and a “1” where it is. These are known as dummy variables.
TensorFlow has several pre-processing libraries that you can use with the ML. For example, tf.transform.
Code your model
Develop your model with established ML techniques or with the definition of new operations and approaches.
Start learning by working with the TensorFlow introduction guide. Do not forget to read the posts of this blog about Tensorflow. You can also follow the scikit-learn documentation or the XGBoost documentation to create your model.
Train, evaluate and adjust your model
In this blog, we have provided everything you need to train and evaluate your model. But there are many more websites that can be useful, look for them!
When you train your model, you feed it with data that you already know the value for your target data attribute (characteristic). You run the model to predict those target values of your training data so that the model can adjust its settings to fit the data better and thus predict the target value more accurately.
Similarly, when you evaluate your trained model, you feed it with data that includes the target values. You compare the results of your model’s predictions with the actual values of the evaluation data and use appropriate statistical techniques for your model to assess that it has no vulnerabilities.
You can also adjust the model if you change the operations or settings you use to control the training process, such as the number of training steps you want to execute. This technique is the adjustment of hyperparameters.
The development of a model is a process of experimentation and incremental adjustment. You should expect to spend a lot of time when you better define and modify your model to get the best results. You must set a threshold without vulnerabilities for your model before you start so that you know when you should stop defining the model better.
Test your model
During training, the application of the model to known data to adjust the settings to improve the results. When your results are good enough for your needs, you must implement the model on any system that uses your application and test it. That is, you must check your model with your broker.
To test your model, run the data in a context as close as possible to your final application and your production infrastructure.
Use a different set of data from the ones you use for training and evaluation. Ideally, you would use a separate data set each time you perform a test so that you evaluate your model with data that it has never processed before.
You may also want to create different sets of test data depending on the nature of your model. For example, you can use different data sets for certain elements or points in time or divide the instances to mimic different demographic data.
During the test process, make adjustments to the hyperparameters and parameters of the model according to the test results. This last can help you identify problems in the model or its interaction with the rest of your application.
We are here
We have made a long journey to get here. The following figure tells us where we are and where we are going.
Therefore, we are close to achieving our first major objective:
“Place automatic orders in our broker”.
Deploy your model
In the next post “Deep Trading with TensorFlow VIII,” we will explain how you can “Save a TensorFlow model” so that TensorFlow Serving ModelServer will load it and use in production. Then Serve your model with the TensorFlow Serving ModelServer and finally “Send requests” to your model (and get responses).
Send prediction requests to your model
Tensorflow serving provides the services you need to request predictions of your model.
There are two ways to obtain predictions from trained models: online prediction and batch prediction.
Monitor your prediction service
Monitor the predictions continuously. It is important not to lose sight of your predictions: You risk your money (or that of your investors)!
Manage your models and model versions
You must be ordered with the versions of your model. TensorFlow serving allows you to manage different versions of the same model. This facilitates the automatic update of the models, but at the same time, it can be a source of errors.
Use your model
Finally you got it. You have a working model and it sends real order to your broker. 🙂
This is the content of next Deep Trading with TensorFlow IX. We will send
So I hope you read our next post to complete the journey!