 Black Belt
Black Belt DeepTrading with TensorFlow VI
Data corrupts. Absolute Data corrupts absolutely. This is my impression every time I am faced with the amount of data that is available to us in the current times.
This is the moment of truth. Today you will learn how to make some predictions in the Forex market. This is probably the Far West of the financial markets.
But you have nothing to fear as I am revealing step by step what could take months and probably years, as it has cost me because I have gone the dark (hard) side.
Making the first prediction in the Forex Market
The progress of the model can be saved during and after training. This means that a model can be resumed where it left off and avoid long training times. Saving also means that you can share your model and others can recreate your work.
We will illustrate how to create a multiple fully connected hidden layer NN, save it and make predictions with trained model after reload it.
Furthermore, we will use the EURUSD data for this exercise.
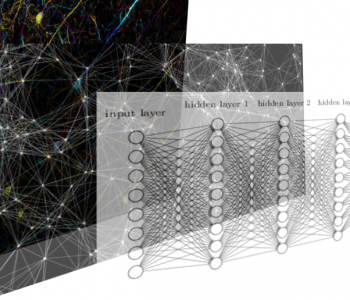
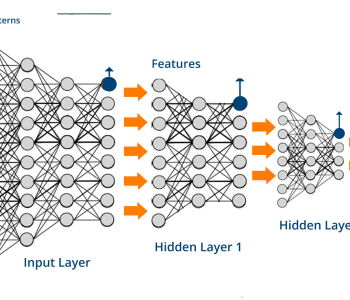
In this post, we will build a four-hidden layer neural network to predict the next close price, from the other four features of the precedent period (open, high, low and close).
This is a practical exercise to learn how to make predictions with TensorFlow, but it is a naive approach to the real forecasting problem. Don’t worry we will be climbing toward better approaches. Also, in the meantime, you will be able to elaborate on your own systems.
Load configuration
Below, it is an example of .env file for your customization:
PROJ_DIR=.
DATA_DIR=../data/
RAW_DIR=../data/raw/
INTERIM_DIR=../data/interim/
PROCESSED_DIR=../data/processed/
FIGURES_DIR=../reports/figures/
MODEL_DIR=../models/
EXTERNAL_DIR=../data/external/
PRODUCTION_DIR=/home/PRODUCTION/In this part of the code we should load all our experiment parameters.
In this
In [1]:
## 1. Import libraries and modules. Load env variables
import os
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#import seaborn as sns
import zipfile
import sqlite3
from datetime import date, datetime, timezone
from dotenv import find_dotenv, load_dotenv
import tensorflow as tf
from tensorflow.python.framework import ops
from tensorflow.python.saved_model import builder as saved_model_builder
from tensorflow.python.saved_model import signature_constants
from tensorflow.python.saved_model import signature_def_utils
from tensorflow.python.saved_model import tag_constants
from tensorflow.python.saved_model.utils import build_tensor_info
from sklearn.preprocessing import MinMaxScaler
#from IPython.display import Image
#Reads the key,value pair from .env and adds them to environment variable
load_dotenv(find_dotenv())
# Check the env variables exist. Check as many variables as you need
raw_msg = "Set your raw data absolute path in the .env file at project root"
assert "RAW_DIR" in os.environ, raw_msg
data_msg = "Set your processed data absolute path in the .env file at project root"
assert "DATA_DIR" in os.environ, data_msg
interim_msg = "Set your interim data absolute path in the .env file at project root"
assert "INTERIM_DIR" in os.environ, interim_msg
# Load env variables
proj_dir = os.path.expanduser(os.environ.get("PROJ_DIR"))
data_dir = os.path.expanduser(os.environ.get("DATA_DIR"))
raw_dir = os.path.expanduser(os.environ.get("RAW_DIR"))
interim_dir = os.path.expanduser(os.environ.get("INTERIM_DIR"))
processed_dir = os.path.expanduser(os.environ.get("PROCESSED_DIR"))
figures_dir = os.path.expanduser(os.environ.get("FIGURES_DIR"))
model_dir = os.path.expanduser(os.environ.get("MODEL_DIR"))
external_dir = os.path.expanduser(os.environ.get("EXTERNAL_DIR"))
production_dir = os.path.expanduser(os.environ.get("PRODUCTION_DIR"))
# Import our project modules
#
#Add src/app to the PATH
#Ram sys.path.append(os.path.join(proj_dir,"src/app"))
#Add src/data to the PATH
sys.path.append(os.path.join(proj_dir,"src/data"))
#Ram import make_dataset as md
#Add src/visualization to the PATH
#Ram sys.path.append(os.path.join(proj_dir,"src/visualization"))
#Ram import visualize as vs
#Data files
#raw_data =
#interim_data =
#Global configuration variables
# Send models to production env. folder (True: send. False: Do not send)
to_production = True
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
/home/parrondo/anaconda3/envs/deeptrading/lib/python3.5/importlib/_bootstrap.py:222: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88
return f(*args, **kwds)
Ingest raw data
Download raw datasets
The great people at HistData.com have set up the infrastructure necessary to provide you FOREX data for free. This is awesome and if possible, you should donate or purchase some of their services to help them. There exist several tools contained on the internet to download the data, but all of them need your careful attention. For example:
- https://github.com/philipperemy/FX-1-Minute-Data
- https://github.com/xeb/forex-histdata-etl
- https://gist.github.com/EvianZhow/93b30edb5e1ac44f3dd2de7ef9a543d9
I include forex time series zipped files needed in this tutorial
In [2]:
## 2. Download raw data sets
#This point must be adapted for each project
Download .csv data file from HistData.com and save in ../data/raw dir
Basic pre-process data
Machine Learning time series algorithms usually require data to be into a single text file in tabular format, with each row representing a timestamp of the input dataset and each column one of its features.
“Prepare” data for Machine Learning is a complex task depending on where the data is stored and where it is obtained from. And doubtless, it is one of the most time-consuming task. Often the Forex data is not available in a single file. They may be distributed across different sources like multiple compressed CSV files, spreadsheets or plain text files, normalized in database tables, or even in NoSql database like MongoDB. So we need a tool to stage, filter, transform when necessary, and finally export to a single flat, text CSV file.
If your Forex data is small and the changes are simple such as adding a derived field or new events you can use a spreadsheet, make the necessary changes, and then export it to a CSV file. Certainly, not too professional. But when the changes are more complex; e.g., joining several sources, filtering a subset of the data, or managing a large number of timestamp rows, you might need a more powerful tool like an RDBMS. MySQL is a great one and it’s free and opensourced. In this tutorial, we have selected SQLite which is enough for our purpose and data size. Here we treat several compressed .csv files distributed in different folders, which is very usual in real trading. If the data size that we are managing is in the terabytes, then we should consider Hadoop. But trust

In [3]:
# All available instruments to trade with
symbol = "EURUSD" # type=str, symbol list using format "EURUSD" "EURGBP"
In [4]:
# Clean database table
DATABASE_FILE = processed_dir+"Data.db"
def initialize_db(self):
with sqlite3.connect(DATABASE_FILE) as connection:
cursor = connection.cursor()
cursor.execute('CREATE TABLE IF NOT EXISTS History (timestamp INTEGER,'
'symbol VARCHAR(20), high FLOAT, low FLOAT,'
'open FLOAT, close FLOAT, volume FLOAT, '
'quoteVolume FLOAT, weightedAverage FLOAT,'
'PRIMARY KEY (timestamp, symbol));')
connection.commit()
initialize_db(DATABASE_FILE)
conn = sqlite3.connect(DATABASE_FILE)
In [5]:
# Create the dataframe
columns = ["timestamp", "symbol", "open", "high", "low", "close", "volume", "quoteVolume", "weightedAverage"]
dtype = {"timestamp":"INTEGER",
"symbol":"VARCHAR(20)",
"open":"FLOAT",
"high":"FLOAT",
"low":"FLOAT",
"close":"FLOAT",
"volume":"FLOAT",
"quoteVolume":"FLOAT",
"weightedAverage":"FLOAT"}
df0 = pd.DataFrame(columns=columns)
# Write dataframe to sqlite database
df0.to_sql("History", conn, if_exists="replace", index=False, dtype=dtype)
In [6]:
#
# Database population
#
#
# All price instrument in cash currency base
#
# Initialicing dataframes
df1 = pd.DataFrame().iloc[0:0]
df2 = pd.DataFrame().iloc[0:0]
# Managing diferent raw data files from several folders
compressedfile = os.path.join(raw_dir,symbol.lower(),'HISTDATA_COM_ASCII_'+symbol+'_M1_2017.zip')
zf = zipfile.ZipFile(compressedfile) # having .csv zipped file
inputfile = 'DAT_ASCII_'+symbol+'_M1_2017.csv'
print("inputfile: ",inputfile)
#df1 = pd.read_csv(inputfile, names=['date', 'open', 'high', 'low', 'close', 'volume'],index_col=0, parse_dates=True, delimiter=";")
df1 = pd.read_csv(zf.open(inputfile), header=None,
names=['timestamp', 'open', 'high', 'low', 'close', 'volume'],
index_col=0, parse_dates=True,sep=';') # reads the csv and creates the dataframe called "df1"
# Resampling data from 1Min to desired Period
df2 = df1["open"].resample('60Min').ohlc()
# Convert pandas timestamps in Unix timestamps:
df2.index = df2.index.astype(np.int64) // 10**9
# Insert new columns with the instrument name and their values
df2.insert(loc=0, column='symbol', value=symbol)
#Only for compatibility with stocks code (optional, you may want to remove this fields from database)
df2['volume']=1000.
df2['quoteVolume']=1000.
df2['weightedAverage']=1.
# Reset index to save in database
df2=df2.reset_index()
#Filling gaps forward
df2 = df2.fillna(method='pad')
# Save to database (Populate database)
df2.to_sql("History", conn, if_exists="append", index=False, chunksize=1000)
# Liberate memory
del df1
del df2
inputfile: DAT_ASCII_EURUSD_M1_2017.csv
In [7]:
# Committing changes and closing the connection to the database file
conn.commit()
conn.close()
Load data from database
In [8]:
# Load dataset (In this case reading the database)
DATABASE_FILE=processed_dir+"Data.db"
conn = sqlite3.connect(DATABASE_FILE)
df = pd.read_sql_query("select * from History;", conn)
df=df.drop(["index"], axis=1, errors="ignore")
In [9]:
df
Out[9]:
| timestamp | symbol | open | high | low | close | volume | quoteVolume | weightedAverage | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1483322400 | EURUSD | 1.05155 | 1.05213 | 1.05130 | 1.05150 | 1000.0 | 1000.0 | 1.0 |
| 1 | 1483326000 | EURUSD | 1.05152 | 1.05175 | 1.04929 | 1.04929 | 1000.0 | 1000.0 | 1.0 |
| 2 | 1483329600 | EURUSD | 1.04889 | 1.04904 | 1.04765 | 1.04868 | 1000.0 | 1000.0 | 1.0 |
| 3 | 1483333200 | EURUSD | 1.04866 | 1.04885 | 1.04791 | 1.04803 | 1000.0 | 1000.0 | 1.0 |
| 4 | 1483336800 | EURUSD | 1.04805 | 1.04812 | 1.04768 | 1.04782 | 1000.0 | 1000.0 | 1.0 |
| 5 | 1483340400 | EURUSD | 1.04782 | 1.04782 | 1.04653 | 1.04659 | 1000.0 | 1000.0 | 1.0 |
| 6 | 1483344000 | EURUSD | 1.04655 | 1.04680 | 1.04615 | 1.04668 | 1000.0 | 1000.0 | 1.0 |
| 7 | 1483347600 | EURUSD | 1.04655 | 1.04747 | 1.04649 | 1.04747 | 1000.0 | 1000.0 | 1.0 |
| 8 | 1483351200 | EURUSD | 1.04718 | 1.04729 | 1.04637 | 1.04699 | 1000.0 | 1000.0 | 1.0 |
| 9 | 1483354800 | EURUSD | 1.04696 | 1.04771 | 1.04676 | 1.04686 | 1000.0 | 1000.0 | 1.0 |
| 10 | 1483358400 | EURUSD | 1.04690 | 1.04690 | 1.04621 | 1.04655 | 1000.0 | 1000.0 | 1.0 |
| 11 | 1483362000 | EURUSD | 1.04654 | 1.04665 | 1.04605 | 1.04605 | 1000.0 | 1000.0 | 1.0 |
| 12 | 1483365600 | EURUSD | 1.04600 | 1.04627 | 1.04581 | 1.04592 | 1000.0 | 1000.0 | 1.0 |
| 13 | 1483369200 | EURUSD | 1.04589 | 1.04597 | 1.04565 | 1.04582 | 1000.0 | 1000.0 | 1.0 |
| 14 | 1483372800 | EURUSD | 1.04582 | 1.04582 | 1.04496 | 1.04525 | 1000.0 | 1000.0 | 1.0 |
| 15 | 1483376400 | EURUSD | 1.04534 | 1.04702 | 1.04532 | 1.04605 | 1000.0 | 1000.0 | 1.0 |
| 16 | 1483380000 | EURUSD | 1.04616 | 1.04678 | 1.04557 | 1.04573 | 1000.0 | 1000.0 | 1.0 |
| 17 | 1483383600 | EURUSD | 1.04572 | 1.04703 | 1.04572 | 1.04662 | 1000.0 | 1000.0 | 1.0 |
| 18 | 1483387200 | EURUSD | 1.04660 | 1.04805 | 1.04659 | 1.04763 | 1000.0 | 1000.0 | 1.0 |
| 19 | 1483390800 | EURUSD | 1.04758 | 1.04772 | 1.04711 | 1.04713 | 1000.0 | 1000.0 | 1.0 |
| 20 | 1483394400 | EURUSD | 1.04717 | 1.04838 | 1.04715 | 1.04838 | 1000.0 | 1000.0 | 1.0 |
| 21 | 1483398000 | EURUSD | 1.04845 | 1.04896 | 1.04824 | 1.04860 | 1000.0 | 1000.0 | 1.0 |
| 22 | 1483401600 | EURUSD | 1.04882 | 1.04896 | 1.04814 | 1.04814 | 1000.0 | 1000.0 | 1.0 |
| 23 | 1483405200 | EURUSD | 1.04820 | 1.04882 | 1.04820 | 1.04863 | 1000.0 | 1000.0 | 1.0 |
| 24 | 1483408800 | EURUSD | 1.04880 | 1.04880 | 1.04539 | 1.04586 | 1000.0 | 1000.0 | 1.0 |
| 25 | 1483412400 | EURUSD | 1.04600 | 1.04641 | 1.04218 | 1.04370 | 1000.0 | 1000.0 | 1.0 |
| 26 | 1483416000 | EURUSD | 1.04351 | 1.04355 | 1.04025 | 1.04100 | 1000.0 | 1000.0 | 1.0 |
| 27 | 1483419600 | EURUSD | 1.04017 | 1.04158 | 1.03972 | 1.03980 | 1000.0 | 1000.0 | 1.0 |
| 28 | 1483423200 | EURUSD | 1.03964 | 1.03976 | 1.03822 | 1.03931 | 1000.0 | 1000.0 | 1.0 |
| 29 | 1483426800 | EURUSD | 1.03941 | 1.03941 | 1.03753 | 1.03852 | 1000.0 | 1000.0 | 1.0 |
| … | … | … | … | … | … | … | … | … | … |
| 8649 | 1514458800 | EURUSD | 1.19366 | 1.19539 | 1.19366 | 1.19520 | 1000.0 | 1000.0 | 1.0 |
| 8650 | 1514462400 | EURUSD | 1.19513 | 1.19547 | 1.19497 | 1.19530 | 1000.0 | 1000.0 | 1.0 |
| 8651 | 1514466000 | EURUSD | 1.19530 | 1.19587 | 1.19530 | 1.19582 | 1000.0 | 1000.0 | 1.0 |
| 8652 | 1514469600 | EURUSD | 1.19578 | 1.19584 | 1.19500 | 1.19519 | 1000.0 | 1000.0 | 1.0 |
| 8653 | 1514473200 | EURUSD | 1.19527 | 1.19527 | 1.19413 | 1.19413 | 1000.0 | 1000.0 | 1.0 |
| 8654 | 1514476800 | EURUSD | 1.19403 | 1.19446 | 1.19391 | 1.19423 | 1000.0 | 1000.0 | 1.0 |
| 8655 | 1514480400 | EURUSD | 1.19415 | 1.19445 | 1.19364 | 1.19379 | 1000.0 | 1000.0 | 1.0 |
| 8656 | 1514484000 | EURUSD | 1.19384 | 1.19409 | 1.19384 | 1.19391 | 1000.0 | 1000.0 | 1.0 |
| 8657 | 1514487600 | EURUSD | 1.19394 | 1.19451 | 1.19393 | 1.19441 | 1000.0 | 1000.0 | 1.0 |
| 8658 | 1514491200 | EURUSD | 1.19441 | 1.19486 | 1.19373 | 1.19419 | 1000.0 | 1000.0 | 1.0 |
| 8659 | 1514494800 | EURUSD | 1.19421 | 1.19474 | 1.19376 | 1.19474 | 1000.0 | 1000.0 | 1.0 |
| 8660 | 1514498400 | EURUSD | 1.19476 | 1.19476 | 1.19418 | 1.19426 | 1000.0 | 1000.0 | 1.0 |
| 8661 | 1514502000 | EURUSD | 1.19426 | 1.19458 | 1.19415 | 1.19443 | 1000.0 | 1000.0 | 1.0 |
| 8662 | 1514505600 | EURUSD | 1.19444 | 1.19473 | 1.19438 | 1.19465 | 1000.0 | 1000.0 | 1.0 |
| 8663 | 1514509200 | EURUSD | 1.19489 | 1.19553 | 1.19487 | 1.19543 | 1000.0 | 1000.0 | 1.0 |
| 8664 | 1514512800 | EURUSD | 1.19551 | 1.19581 | 1.19464 | 1.19525 | 1000.0 | 1000.0 | 1.0 |
| 8665 | 1514516400 | EURUSD | 1.19523 | 1.19685 | 1.19523 | 1.19674 | 1000.0 | 1000.0 | 1.0 |
| 8666 | 1514520000 | EURUSD | 1.19674 | 1.19870 | 1.19674 | 1.19829 | 1000.0 | 1000.0 | 1.0 |
| 8667 | 1514523600 | EURUSD | 1.19814 | 1.19848 | 1.19736 | 1.19806 | 1000.0 | 1000.0 | 1.0 |
| 8668 | 1514527200 | EURUSD | 1.19803 | 1.19887 | 1.19800 | 1.19867 | 1000.0 | 1000.0 | 1.0 |
| 8669 | 1514530800 | EURUSD | 1.19870 | 1.19946 | 1.19849 | 1.19946 | 1000.0 | 1000.0 | 1.0 |
| 8670 | 1514534400 | EURUSD | 1.19951 | 1.19983 | 1.19839 | 1.19846 | 1000.0 | 1000.0 | 1.0 |
| 8671 | 1514538000 | EURUSD | 1.19867 | 1.19946 | 1.19861 | 1.19926 | 1000.0 | 1000.0 | 1.0 |
| 8672 | 1514541600 | EURUSD | 1.19927 | 1.20069 | 1.19880 | 1.20069 | 1000.0 | 1000.0 | 1.0 |
| 8673 | 1514545200 | EURUSD | 1.20097 | 1.20215 | 1.20023 | 1.20215 | 1000.0 | 1000.0 | 1.0 |
| 8674 | 1514548800 | EURUSD | 1.20220 | 1.20255 | 1.20193 | 1.20197 | 1000.0 | 1000.0 | 1.0 |
| 8675 | 1514552400 | EURUSD | 1.20214 | 1.20231 | 1.20124 | 1.20133 | 1000.0 | 1000.0 | 1.0 |
| 8676 | 1514556000 | EURUSD | 1.20134 | 1.20138 | 1.20071 | 1.20106 | 1000.0 | 1000.0 | 1.0 |
| 8677 | 1514559600 | EURUSD | 1.20092 | 1.20104 | 1.19978 | 1.19983 | 1000.0 | 1000.0 | 1.0 |
| 8678 | 1514563200 | EURUSD | 1.19978 | 1.20035 | 1.19927 | 1.19982 | 1000.0 | 1000.0 | 1.0 |
8679 rows × 9 columns
In [10]:
df1 = df.loc[(df['symbol'] == "EURUSD"),['timestamp','open','high','low','close']]
In [11]:
df1
Out[11]:
| timestamp | open | high | low | close | |
|---|---|---|---|---|---|
| 0 | 1483322400 | 1.05155 | 1.05213 | 1.05130 | 1.05150 |
| 1 | 1483326000 | 1.05152 | 1.05175 | 1.04929 | 1.04929 |
| 2 | 1483329600 | 1.04889 | 1.04904 | 1.04765 | 1.04868 |
| 3 | 1483333200 | 1.04866 | 1.04885 | 1.04791 | 1.04803 |
| 4 | 1483336800 | 1.04805 | 1.04812 | 1.04768 | 1.04782 |
| 5 | 1483340400 | 1.04782 | 1.04782 | 1.04653 | 1.04659 |
| 6 | 1483344000 | 1.04655 | 1.04680 | 1.04615 | 1.04668 |
| 7 | 1483347600 | 1.04655 | 1.04747 | 1.04649 | 1.04747 |
| 8 | 1483351200 | 1.04718 | 1.04729 | 1.04637 | 1.04699 |
| 9 | 1483354800 | 1.04696 | 1.04771 | 1.04676 | 1.04686 |
| 10 | 1483358400 | 1.04690 | 1.04690 | 1.04621 | 1.04655 |
| 11 | 1483362000 | 1.04654 | 1.04665 | 1.04605 | 1.04605 |
| 12 | 1483365600 | 1.04600 | 1.04627 | 1.04581 | 1.04592 |
| 13 | 1483369200 | 1.04589 | 1.04597 | 1.04565 | 1.04582 |
| 14 | 1483372800 | 1.04582 | 1.04582 | 1.04496 | 1.04525 |
| 15 | 1483376400 | 1.04534 | 1.04702 | 1.04532 | 1.04605 |
| 16 | 1483380000 | 1.04616 | 1.04678 | 1.04557 | 1.04573 |
| 17 | 1483383600 | 1.04572 | 1.04703 | 1.04572 | 1.04662 |
| 18 | 1483387200 | 1.04660 | 1.04805 | 1.04659 | 1.04763 |
| 19 | 1483390800 | 1.04758 | 1.04772 | 1.04711 | 1.04713 |
| 20 | 1483394400 | 1.04717 | 1.04838 | 1.04715 | 1.04838 |
| 21 | 1483398000 | 1.04845 | 1.04896 | 1.04824 | 1.04860 |
| 22 | 1483401600 | 1.04882 | 1.04896 | 1.04814 | 1.04814 |
| 23 | 1483405200 | 1.04820 | 1.04882 | 1.04820 | 1.04863 |
| 24 | 1483408800 | 1.04880 | 1.04880 | 1.04539 | 1.04586 |
| 25 | 1483412400 | 1.04600 | 1.04641 | 1.04218 | 1.04370 |
| 26 | 1483416000 | 1.04351 | 1.04355 | 1.04025 | 1.04100 |
| 27 | 1483419600 | 1.04017 | 1.04158 | 1.03972 | 1.03980 |
| 28 | 1483423200 | 1.03964 | 1.03976 | 1.03822 | 1.03931 |
| 29 | 1483426800 | 1.03941 | 1.03941 | 1.03753 | 1.03852 |
| … | … | … | … | … | … |
| 8649 | 1514458800 | 1.19366 | 1.19539 | 1.19366 | 1.19520 |
| 8650 | 1514462400 | 1.19513 | 1.19547 | 1.19497 | 1.19530 |
| 8651 | 1514466000 | 1.19530 | 1.19587 | 1.19530 | 1.19582 |
| 8652 | 1514469600 | 1.19578 | 1.19584 | 1.19500 | 1.19519 |
| 8653 | 1514473200 | 1.19527 | 1.19527 | 1.19413 | 1.19413 |
| 8654 | 1514476800 | 1.19403 | 1.19446 | 1.19391 | 1.19423 |
| 8655 | 1514480400 | 1.19415 | 1.19445 | 1.19364 | 1.19379 |
| 8656 | 1514484000 | 1.19384 | 1.19409 | 1.19384 | 1.19391 |
| 8657 | 1514487600 | 1.19394 | 1.19451 | 1.19393 | 1.19441 |
| 8658 | 1514491200 | 1.19441 | 1.19486 | 1.19373 | 1.19419 |
| 8659 | 1514494800 | 1.19421 | 1.19474 | 1.19376 | 1.19474 |
| 8660 | 1514498400 | 1.19476 | 1.19476 | 1.19418 | 1.19426 |
| 8661 | 1514502000 | 1.19426 | 1.19458 | 1.19415 | 1.19443 |
| 8662 | 1514505600 | 1.19444 | 1.19473 | 1.19438 | 1.19465 |
| 8663 | 1514509200 | 1.19489 | 1.19553 | 1.19487 | 1.19543 |
| 8664 | 1514512800 | 1.19551 | 1.19581 | 1.19464 | 1.19525 |
| 8665 | 1514516400 | 1.19523 | 1.19685 | 1.19523 | 1.19674 |
| 8666 | 1514520000 | 1.19674 | 1.19870 | 1.19674 | 1.19829 |
| 8667 | 1514523600 | 1.19814 | 1.19848 | 1.19736 | 1.19806 |
| 8668 | 1514527200 | 1.19803 | 1.19887 | 1.19800 | 1.19867 |
| 8669 | 1514530800 | 1.19870 | 1.19946 | 1.19849 | 1.19946 |
| 8670 | 1514534400 | 1.19951 | 1.19983 | 1.19839 | 1.19846 |
| 8671 | 1514538000 | 1.19867 | 1.19946 | 1.19861 | 1.19926 |
| 8672 | 1514541600 | 1.19927 | 1.20069 | 1.19880 | 1.20069 |
| 8673 | 1514545200 | 1.20097 | 1.20215 | 1.20023 | 1.20215 |
| 8674 | 1514548800 | 1.20220 | 1.20255 | 1.20193 | 1.20197 |
| 8675 | 1514552400 | 1.20214 | 1.20231 | 1.20124 | 1.20133 |
| 8676 | 1514556000 | 1.20134 | 1.20138 | 1.20071 | 1.20106 |
| 8677 | 1514559600 | 1.20092 | 1.20104 | 1.19978 | 1.19983 |
| 8678 | 1514563200 | 1.19978 | 1.20035 | 1.19927 | 1.19982 |
8679 rows × 5 columns In [12]:
# Create the apropiate features dataframe (In this case is open, high, low and close prices of symbol)
df2 = pd.DataFrame()
symbol_features = ['open', 'high', 'low', 'close']
for feature in symbol_features:
df1 = df.loc[(df['symbol'] == symbol),['timestamp', feature]]
df1.columns=['timestamp',symbol+feature]
# Setting the timestamp as the index
df1.set_index('timestamp', inplace=True)
# Convert timestamps to dates but it's not mandatory
#df1.index = pd.to_datetime(df1.index, unit='s')
# Just perform a join and that's it
df2 = df2.join(df1, how='outer')
# Filling the remaining gaps backguards (the initial gaps has not before value)
df2 = df2.fillna(method='bfill')
# Independent variables data
X_raw = df2
# Dimensions of dataset
print("Dimensions of dataset")
n = X_raw.shape[0]
p = X_raw.shape[1]
print("n=",n,"p=",p)
# Drop timestamp variable (only when necessary)
#Ram print("Drop timestamp variable")
#Ram X_raw = X_raw.drop(['timestamp'], 1)
Dimensions of dataset
n= 8679 p= 4
In [13]:
X_raw
Out[13]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| timestamp | ||||
| 1483322400 | 1.05155 | 1.05213 | 1.05130 | 1.05150 |
| 1483326000 | 1.05152 | 1.05175 | 1.04929 | 1.04929 |
| 1483329600 | 1.04889 | 1.04904 | 1.04765 | 1.04868 |
| 1483333200 | 1.04866 | 1.04885 | 1.04791 | 1.04803 |
| 1483336800 | 1.04805 | 1.04812 | 1.04768 | 1.04782 |
| 1483340400 | 1.04782 | 1.04782 | 1.04653 | 1.04659 |
| 1483344000 | 1.04655 | 1.04680 | 1.04615 | 1.04668 |
| 1483347600 | 1.04655 | 1.04747 | 1.04649 | 1.04747 |
| 1483351200 | 1.04718 | 1.04729 | 1.04637 | 1.04699 |
| 1483354800 | 1.04696 | 1.04771 | 1.04676 | 1.04686 |
| 1483358400 | 1.04690 | 1.04690 | 1.04621 | 1.04655 |
| 1483362000 | 1.04654 | 1.04665 | 1.04605 | 1.04605 |
| 1483365600 | 1.04600 | 1.04627 | 1.04581 | 1.04592 |
| 1483369200 | 1.04589 | 1.04597 | 1.04565 | 1.04582 |
| 1483372800 | 1.04582 | 1.04582 | 1.04496 | 1.04525 |
| 1483376400 | 1.04534 | 1.04702 | 1.04532 | 1.04605 |
| 1483380000 | 1.04616 | 1.04678 | 1.04557 | 1.04573 |
| 1483383600 | 1.04572 | 1.04703 | 1.04572 | 1.04662 |
| 1483387200 | 1.04660 | 1.04805 | 1.04659 | 1.04763 |
| 1483390800 | 1.04758 | 1.04772 | 1.04711 | 1.04713 |
| 1483394400 | 1.04717 | 1.04838 | 1.04715 | 1.04838 |
| 1483398000 | 1.04845 | 1.04896 | 1.04824 | 1.04860 |
| 1483401600 | 1.04882 | 1.04896 | 1.04814 | 1.04814 |
| 1483405200 | 1.04820 | 1.04882 | 1.04820 | 1.04863 |
| 1483408800 | 1.04880 | 1.04880 | 1.04539 | 1.04586 |
| 1483412400 | 1.04600 | 1.04641 | 1.04218 | 1.04370 |
| 1483416000 | 1.04351 | 1.04355 | 1.04025 | 1.04100 |
| 1483419600 | 1.04017 | 1.04158 | 1.03972 | 1.03980 |
| 1483423200 | 1.03964 | 1.03976 | 1.03822 | 1.03931 |
| 1483426800 | 1.03941 | 1.03941 | 1.03753 | 1.03852 |
| … | … | … | … | … |
| 1514458800 | 1.19366 | 1.19539 | 1.19366 | 1.19520 |
| 1514462400 | 1.19513 | 1.19547 | 1.19497 | 1.19530 |
| 1514466000 | 1.19530 | 1.19587 | 1.19530 | 1.19582 |
| 1514469600 | 1.19578 | 1.19584 | 1.19500 | 1.19519 |
| 1514473200 | 1.19527 | 1.19527 | 1.19413 | 1.19413 |
| 1514476800 | 1.19403 | 1.19446 | 1.19391 | 1.19423 |
| 1514480400 | 1.19415 | 1.19445 | 1.19364 | 1.19379 |
| 1514484000 | 1.19384 | 1.19409 | 1.19384 | 1.19391 |
| 1514487600 | 1.19394 | 1.19451 | 1.19393 | 1.19441 |
| 1514491200 | 1.19441 | 1.19486 | 1.19373 | 1.19419 |
| 1514494800 | 1.19421 | 1.19474 | 1.19376 | 1.19474 |
| 1514498400 | 1.19476 | 1.19476 | 1.19418 | 1.19426 |
| 1514502000 | 1.19426 | 1.19458 | 1.19415 | 1.19443 |
| 1514505600 | 1.19444 | 1.19473 | 1.19438 | 1.19465 |
| 1514509200 | 1.19489 | 1.19553 | 1.19487 | 1.19543 |
| 1514512800 | 1.19551 | 1.19581 | 1.19464 | 1.19525 |
| 1514516400 | 1.19523 | 1.19685 | 1.19523 | 1.19674 |
| 1514520000 | 1.19674 | 1.19870 | 1.19674 | 1.19829 |
| 1514523600 | 1.19814 | 1.19848 | 1.19736 | 1.19806 |
| 1514527200 | 1.19803 | 1.19887 | 1.19800 | 1.19867 |
| 1514530800 | 1.19870 | 1.19946 | 1.19849 | 1.19946 |
| 1514534400 | 1.19951 | 1.19983 | 1.19839 | 1.19846 |
| 1514538000 | 1.19867 | 1.19946 | 1.19861 | 1.19926 |
| 1514541600 | 1.19927 | 1.20069 | 1.19880 | 1.20069 |
| 1514545200 | 1.20097 | 1.20215 | 1.20023 | 1.20215 |
| 1514548800 | 1.20220 | 1.20255 | 1.20193 | 1.20197 |
| 1514552400 | 1.20214 | 1.20231 | 1.20124 | 1.20133 |
| 1514556000 | 1.20134 | 1.20138 | 1.20071 | 1.20106 |
| 1514559600 | 1.20092 | 1.20104 | 1.19978 | 1.19983 |
| 1514563200 | 1.19978 | 1.20035 | 1.19927 | 1.19982 |
8679 rows × 4 columns
In [14]:
# Target
# We use as target one of the symbols rate, i.e. "EURUSD". That is we try to predict next value of EURUSD
lag = -1
y_raw = df2.loc[:,"EURUSDclose"].shift(periods=lag)
In [15]:
#
# Removal of Null values**
# Now since there still exists 'NaN' values in our target dataframe, and these are Null values,
# we have to do something about them. In here, I will just do the naive thing of replacing these NaNs
# with previous value because it is only the last value an error is negligible as such:
# Filling gaps forward
y_raw = y_raw.fillna(method='pad')
y_raw
# Drop timestamp variable (only when necessary)
#Ram print("Drop timestamp variable")
#Ram y_raw = data.drop(['timestamp'], 1)
Out[15]:
timestamp
1483322400 1.04929
1483326000 1.04868
1483329600 1.04803
1483333200 1.04782
1483336800 1.04659
1483340400 1.04668
1483344000 1.04747
1483347600 1.04699
1483351200 1.04686
1483354800 1.04655
1483358400 1.04605
1483362000 1.04592
1483365600 1.04582
1483369200 1.04525
1483372800 1.04605
1483376400 1.04573
1483380000 1.04662
1483383600 1.04763
1483387200 1.04713
1483390800 1.04838
1483394400 1.04860
1483398000 1.04814
1483401600 1.04863
1483405200 1.04586
1483408800 1.04370
1483412400 1.04100
1483416000 1.03980
1483419600 1.03931
1483423200 1.03852
1483426800 1.03910
...
1514458800 1.19530
1514462400 1.19582
1514466000 1.19519
1514469600 1.19413
1514473200 1.19423
1514476800 1.19379
1514480400 1.19391
1514484000 1.19441
1514487600 1.19419
1514491200 1.19474
1514494800 1.19426
1514498400 1.19443
1514502000 1.19465
1514505600 1.19543
1514509200 1.19525
1514512800 1.19674
1514516400 1.19829
1514520000 1.19806
1514523600 1.19867
1514527200 1.19946
1514530800 1.19846
1514534400 1.19926
1514538000 1.20069
1514541600 1.20215
1514545200 1.20197
1514548800 1.20133
1514552400 1.20106
1514556000 1.19983
1514559600 1.19982
1514563200 1.19982
Name: EURUSDclose, Length: 8679, dtype: float64In [16]:
#A quick look at the dataframe time series using pyplot.plot(X_raw['EURUSD']):
plt.plot(X_raw['EURUSDclose'])
Out[16]:
[<matplotlib.lines.Line2D at 0x7f109dd4b240>]

Split data
In [17]:
# split into train and test sets
# Total samples
nsamples = n
# Splitting into train (70%) and test (30%) sets
split = 90 # training split% ; test (100-split)%
jindex = nsamples*split//100 # Index for slicing the samples
# Samples in train
nsamples_train = jindex
# Samples in test
nsamples_test = nsamples - nsamples_train
print("Total number of samples: ",nsamples,"\nSamples in train set: ", nsamples_train,
"\nSamples in test set: ",nsamples_test)
# Here are train and test samples
X_train = X_raw.values[:jindex, :]
y_train = y_raw.values[:jindex]
X_test = X_raw.values[jindex:, :]
y_test = y_raw.values[jindex:]
print("X_train.shape = ", X_train.shape, "y_train.shape =", y_train.shape, "\nX_test.shape = ",
X_test.shape, "y_test.shape = ", y_test.shape)
Total number of samples: 8679
Samples in train set: 7811
Samples in test set: 868
X_train.shape = (7811, 4) y_train.shape = (7811,)
X_test.shape = (868, 4) y_test.shape = (868,)
In [18]:
#X_train as dataframe (optional, only for printing. See note in the beginning)
X_Train = pd.DataFrame(data=X_train)
X_Train.columns = X_raw.columns
print("X_train")
X_Train
X_train
Out[18]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| 0 | 1.05155 | 1.05213 | 1.05130 | 1.05150 |
| 1 | 1.05152 | 1.05175 | 1.04929 | 1.04929 |
| 2 | 1.04889 | 1.04904 | 1.04765 | 1.04868 |
| 3 | 1.04866 | 1.04885 | 1.04791 | 1.04803 |
| 4 | 1.04805 | 1.04812 | 1.04768 | 1.04782 |
| 5 | 1.04782 | 1.04782 | 1.04653 | 1.04659 |
| 6 | 1.04655 | 1.04680 | 1.04615 | 1.04668 |
| 7 | 1.04655 | 1.04747 | 1.04649 | 1.04747 |
| 8 | 1.04718 | 1.04729 | 1.04637 | 1.04699 |
| 9 | 1.04696 | 1.04771 | 1.04676 | 1.04686 |
| 10 | 1.04690 | 1.04690 | 1.04621 | 1.04655 |
| 11 | 1.04654 | 1.04665 | 1.04605 | 1.04605 |
| 12 | 1.04600 | 1.04627 | 1.04581 | 1.04592 |
| 13 | 1.04589 | 1.04597 | 1.04565 | 1.04582 |
| 14 | 1.04582 | 1.04582 | 1.04496 | 1.04525 |
| 15 | 1.04534 | 1.04702 | 1.04532 | 1.04605 |
| 16 | 1.04616 | 1.04678 | 1.04557 | 1.04573 |
| 17 | 1.04572 | 1.04703 | 1.04572 | 1.04662 |
| 18 | 1.04660 | 1.04805 | 1.04659 | 1.04763 |
| 19 | 1.04758 | 1.04772 | 1.04711 | 1.04713 |
| 20 | 1.04717 | 1.04838 | 1.04715 | 1.04838 |
| 21 | 1.04845 | 1.04896 | 1.04824 | 1.04860 |
| 22 | 1.04882 | 1.04896 | 1.04814 | 1.04814 |
| 23 | 1.04820 | 1.04882 | 1.04820 | 1.04863 |
| 24 | 1.04880 | 1.04880 | 1.04539 | 1.04586 |
| 25 | 1.04600 | 1.04641 | 1.04218 | 1.04370 |
| 26 | 1.04351 | 1.04355 | 1.04025 | 1.04100 |
| 27 | 1.04017 | 1.04158 | 1.03972 | 1.03980 |
| 28 | 1.03964 | 1.03976 | 1.03822 | 1.03931 |
| 29 | 1.03941 | 1.03941 | 1.03753 | 1.03852 |
| … | … | … | … | … |
| 7781 | 1.17528 | 1.17528 | 1.17381 | 1.17411 |
| 7782 | 1.17422 | 1.17540 | 1.17418 | 1.17498 |
| 7783 | 1.17506 | 1.17774 | 1.17506 | 1.17761 |
| 7784 | 1.17758 | 1.17961 | 1.17720 | 1.17852 |
| 7785 | 1.17860 | 1.17974 | 1.17834 | 1.17861 |
| 7786 | 1.17886 | 1.17976 | 1.17865 | 1.17945 |
| 7787 | 1.17952 | 1.17986 | 1.17929 | 1.17985 |
| 7788 | 1.17986 | 1.18251 | 1.17959 | 1.18191 |
| 7789 | 1.18250 | 1.18250 | 1.18142 | 1.18186 |
| 7790 | 1.18199 | 1.18244 | 1.18187 | 1.18222 |
| 7791 | 1.18205 | 1.18212 | 1.18166 | 1.18178 |
| 7792 | 1.18179 | 1.18205 | 1.18139 | 1.18139 |
| 7793 | 1.18146 | 1.18202 | 1.18139 | 1.18139 |
| 7794 | 1.18142 | 1.18242 | 1.18142 | 1.18229 |
| 7795 | 1.18228 | 1.18246 | 1.18178 | 1.18214 |
| 7796 | 1.18207 | 1.18376 | 1.18193 | 1.18324 |
| 7797 | 1.18322 | 1.18372 | 1.18322 | 1.18343 |
| 7798 | 1.18346 | 1.18372 | 1.18257 | 1.18288 |
| 7799 | 1.18294 | 1.18346 | 1.18270 | 1.18280 |
| 7800 | 1.18281 | 1.18381 | 1.18249 | 1.18299 |
| 7801 | 1.18263 | 1.18447 | 1.18263 | 1.18425 |
| 7802 | 1.18444 | 1.18465 | 1.18365 | 1.18431 |
| 7803 | 1.18424 | 1.18444 | 1.18383 | 1.18404 |
| 7804 | 1.18465 | 1.18510 | 1.18423 | 1.18463 |
| 7805 | 1.18454 | 1.18529 | 1.18410 | 1.18429 |
| 7806 | 1.18432 | 1.18489 | 1.18430 | 1.18489 |
| 7807 | 1.18492 | 1.18519 | 1.18460 | 1.18466 |
| 7808 | 1.18457 | 1.18534 | 1.18451 | 1.18460 |
| 7809 | 1.18430 | 1.18497 | 1.18402 | 1.18496 |
| 7810 | 1.18506 | 1.18539 | 1.18474 | 1.18490 |
7811 rows × 4 columns In [19]:
#X_test as dataframe (optional, only for printing. See note in the beginning)
X_Test = pd.DataFrame(data=X_test)
X_Test.columns = X_raw.columns
print("X_test")
X_Test
X_test
Out[19]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| 0 | 1.18488 | 1.18531 | 1.18483 | 1.18488 |
| 1 | 1.18504 | 1.18514 | 1.18462 | 1.18514 |
| 2 | 1.18512 | 1.18527 | 1.18493 | 1.18502 |
| 3 | 1.18514 | 1.18514 | 1.18463 | 1.18490 |
| 4 | 1.18478 | 1.18507 | 1.18452 | 1.18496 |
| 5 | 1.18498 | 1.18527 | 1.18477 | 1.18503 |
| 6 | 1.18501 | 1.18544 | 1.18398 | 1.18427 |
| 7 | 1.18429 | 1.18495 | 1.18371 | 1.18476 |
| 8 | 1.18481 | 1.18555 | 1.18481 | 1.18534 |
| 9 | 1.18552 | 1.18552 | 1.18437 | 1.18479 |
| 10 | 1.18483 | 1.18587 | 1.18464 | 1.18526 |
| 11 | 1.18523 | 1.18547 | 1.18502 | 1.18531 |
| 12 | 1.18515 | 1.18534 | 1.18437 | 1.18474 |
| 13 | 1.18472 | 1.18501 | 1.18377 | 1.18431 |
| 14 | 1.18474 | 1.18640 | 1.18446 | 1.18619 |
| 15 | 1.18584 | 1.18744 | 1.18584 | 1.18689 |
| 16 | 1.18681 | 1.18696 | 1.18627 | 1.18659 |
| 17 | 1.18663 | 1.18683 | 1.18560 | 1.18582 |
| 18 | 1.18565 | 1.18732 | 1.18565 | 1.18724 |
| 19 | 1.18739 | 1.18975 | 1.18729 | 1.18968 |
| 20 | 1.18963 | 1.19197 | 1.18962 | 1.19197 |
| 21 | 1.19192 | 1.19352 | 1.19192 | 1.19352 |
| 22 | 1.19342 | 1.19435 | 1.19317 | 1.19357 |
| 23 | 1.19364 | 1.19366 | 1.19239 | 1.19274 |
| 24 | 1.19274 | 1.19326 | 1.19230 | 1.19258 |
| 25 | 1.19253 | 1.19287 | 1.19239 | 1.19264 |
| 26 | 1.19265 | 1.19314 | 1.19256 | 1.19303 |
| 27 | 1.19299 | 1.19381 | 1.19285 | 1.19285 |
| 28 | 1.19299 | 1.19381 | 1.19285 | 1.19285 |
| 29 | 1.19299 | 1.19381 | 1.19285 | 1.19285 |
| … | … | … | … | … |
| 838 | 1.19366 | 1.19539 | 1.19366 | 1.19520 |
| 839 | 1.19513 | 1.19547 | 1.19497 | 1.19530 |
| 840 | 1.19530 | 1.19587 | 1.19530 | 1.19582 |
| 841 | 1.19578 | 1.19584 | 1.19500 | 1.19519 |
| 842 | 1.19527 | 1.19527 | 1.19413 | 1.19413 |
| 843 | 1.19403 | 1.19446 | 1.19391 | 1.19423 |
| 844 | 1.19415 | 1.19445 | 1.19364 | 1.19379 |
| 845 | 1.19384 | 1.19409 | 1.19384 | 1.19391 |
| 846 | 1.19394 | 1.19451 | 1.19393 | 1.19441 |
| 847 | 1.19441 | 1.19486 | 1.19373 | 1.19419 |
| 848 | 1.19421 | 1.19474 | 1.19376 | 1.19474 |
| 849 | 1.19476 | 1.19476 | 1.19418 | 1.19426 |
| 850 | 1.19426 | 1.19458 | 1.19415 | 1.19443 |
| 851 | 1.19444 | 1.19473 | 1.19438 | 1.19465 |
| 852 | 1.19489 | 1.19553 | 1.19487 | 1.19543 |
| 853 | 1.19551 | 1.19581 | 1.19464 | 1.19525 |
| 854 | 1.19523 | 1.19685 | 1.19523 | 1.19674 |
| 855 | 1.19674 | 1.19870 | 1.19674 | 1.19829 |
| 856 | 1.19814 | 1.19848 | 1.19736 | 1.19806 |
| 857 | 1.19803 | 1.19887 | 1.19800 | 1.19867 |
| 858 | 1.19870 | 1.19946 | 1.19849 | 1.19946 |
| 859 | 1.19951 | 1.19983 | 1.19839 | 1.19846 |
| 860 | 1.19867 | 1.19946 | 1.19861 | 1.19926 |
| 861 | 1.19927 | 1.20069 | 1.19880 | 1.20069 |
| 862 | 1.20097 | 1.20215 | 1.20023 | 1.20215 |
| 863 | 1.20220 | 1.20255 | 1.20193 | 1.20197 |
| 864 | 1.20214 | 1.20231 | 1.20124 | 1.20133 |
| 865 | 1.20134 | 1.20138 | 1.20071 | 1.20106 |
| 866 | 1.20092 | 1.20104 | 1.19978 | 1.19983 |
| 867 | 1.19978 | 1.20035 | 1.19927 | 1.19982 |
868 rows × 4 columns
Transform features
Note
Be careful not to write X_test_std = sc.fit_transform(X_test) instead of X_test_std = sc.transform(X_test). In this case, it wouldn’t make a great difference since the mean and standard deviation of the test set should be (quite) similar to the training set. However, this is not always the case in Forex market data, as has been well established in the literature. The correct way is to re-use parameters from the training set if we are doing any kind of transformation. So, the test set should basically stand for “new, unseen” data.
Pay special attention to how the data changes before and after the transformation. This way you will get a better feeling on the information you are handling.
In [20]:
# Scale data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
y_train_std = sc.fit_transform(y_train.reshape(-1, 1))
y_test_std = sc.transform(y_test.reshape(-1, 1))
In [21]:
print("Mean:",sc.mean_)
print("Variance",sc.var_)
Mean: [1.12383816] Variance [0.00252308]
In [22]:
#X_train_std as dataframe (optional, only for printing. See note in the beginning)
X_Train_std = pd.DataFrame(data=X_train_std)
X_Train_std.columns = X_Train.columns
print("X_train_std")
X_Train_std
X_train_std
Out[22]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| 0 | -1.438023 | -1.438023 | -1.431822 | -1.439736 |
| 1 | -1.438620 | -1.445583 | -1.471819 | -1.483732 |
| 2 | -1.490953 | -1.499494 | -1.504453 | -1.495876 |
| 3 | -1.495530 | -1.503274 | -1.499280 | -1.508816 |
| 4 | -1.507668 | -1.517796 | -1.503856 | -1.512996 |
| 5 | -1.512245 | -1.523764 | -1.526740 | -1.537483 |
| 6 | -1.537517 | -1.544055 | -1.534302 | -1.535691 |
| 7 | -1.537517 | -1.530727 | -1.527536 | -1.519964 |
| 8 | -1.524980 | -1.534307 | -1.529924 | -1.529519 |
| 9 | -1.529358 | -1.525952 | -1.522163 | -1.532107 |
| 10 | -1.530552 | -1.542066 | -1.533108 | -1.538279 |
| 11 | -1.537716 | -1.547039 | -1.536292 | -1.548233 |
| 12 | -1.548461 | -1.554599 | -1.541067 | -1.550821 |
| 13 | -1.550650 | -1.560567 | -1.544251 | -1.552811 |
| 14 | -1.552043 | -1.563551 | -1.557981 | -1.564159 |
| 15 | -1.561594 | -1.539679 | -1.550818 | -1.548233 |
| 16 | -1.545277 | -1.544453 | -1.545843 | -1.554603 |
| 17 | -1.554033 | -1.539480 | -1.542858 | -1.536885 |
| 18 | -1.536522 | -1.519188 | -1.525546 | -1.516779 |
| 19 | -1.517021 | -1.525753 | -1.515199 | -1.526732 |
| 20 | -1.525179 | -1.512624 | -1.514403 | -1.501848 |
| 21 | -1.499709 | -1.501085 | -1.492713 | -1.497468 |
| 22 | -1.492346 | -1.501085 | -1.494703 | -1.506626 |
| 23 | -1.504684 | -1.503871 | -1.493509 | -1.496871 |
| 24 | -1.492744 | -1.504268 | -1.549425 | -1.552015 |
| 25 | -1.548461 | -1.551814 | -1.613301 | -1.595015 |
| 26 | -1.598009 | -1.608709 | -1.651706 | -1.648766 |
| 27 | -1.664471 | -1.647899 | -1.662252 | -1.672655 |
| 28 | -1.675017 | -1.684105 | -1.692101 | -1.682410 |
| 29 | -1.679594 | -1.691067 | -1.705831 | -1.698137 |
| … | … | … | … | … |
| 7781 | 1.024055 | 1.011850 | 1.006000 | 1.001130 |
| 7782 | 1.002962 | 1.014237 | 1.013363 | 1.018449 |
| 7783 | 1.019677 | 1.060788 | 1.030874 | 1.070806 |
| 7784 | 1.069822 | 1.097988 | 1.073458 | 1.088922 |
| 7785 | 1.090119 | 1.100575 | 1.096143 | 1.090714 |
| 7786 | 1.095292 | 1.100972 | 1.102311 | 1.107436 |
| 7787 | 1.108426 | 1.102962 | 1.115047 | 1.115399 |
| 7788 | 1.115191 | 1.155679 | 1.121016 | 1.156409 |
| 7789 | 1.167724 | 1.155480 | 1.157431 | 1.155413 |
| 7790 | 1.157576 | 1.154287 | 1.166386 | 1.162580 |
| 7791 | 1.158770 | 1.147921 | 1.162207 | 1.153821 |
| 7792 | 1.153596 | 1.146528 | 1.156834 | 1.146057 |
| 7793 | 1.147029 | 1.145932 | 1.156834 | 1.146057 |
| 7794 | 1.146233 | 1.153889 | 1.157431 | 1.163973 |
| 7795 | 1.163346 | 1.154685 | 1.164595 | 1.160987 |
| 7796 | 1.159168 | 1.180546 | 1.167580 | 1.182886 |
| 7797 | 1.182051 | 1.179750 | 1.193250 | 1.186668 |
| 7798 | 1.186827 | 1.179750 | 1.180315 | 1.175719 |
| 7799 | 1.176480 | 1.174578 | 1.182902 | 1.174126 |
| 7800 | 1.173893 | 1.181541 | 1.178723 | 1.177909 |
| 7801 | 1.170311 | 1.194670 | 1.181509 | 1.202992 |
| 7802 | 1.206328 | 1.198251 | 1.201806 | 1.204187 |
| 7803 | 1.202348 | 1.194074 | 1.205388 | 1.198812 |
| 7804 | 1.210506 | 1.207203 | 1.213347 | 1.210557 |
| 7805 | 1.208318 | 1.210983 | 1.210761 | 1.203789 |
| 7806 | 1.203940 | 1.203026 | 1.214740 | 1.215733 |
| 7807 | 1.215879 | 1.208994 | 1.220710 | 1.211154 |
| 7808 | 1.208915 | 1.211978 | 1.218919 | 1.209960 |
| 7809 | 1.203542 | 1.204617 | 1.209169 | 1.217127 |
| 7810 | 1.218665 | 1.212972 | 1.223496 | 1.215932 |
7811 rows × 4 columns In [23]:
#X_train_std as dataframe (optional, only for printing. See note in the beginning)
X_Test_std = pd.DataFrame(data=X_test_std)
X_Test_std.columns = X_Test.columns
print("X_test_std")
X_Test_std
X_test_std
Out[23]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| 0 | 1.215083 | 1.211381 | 1.225287 | 1.215534 |
| 1 | 1.218267 | 1.207999 | 1.221108 | 1.220710 |
| 2 | 1.219859 | 1.210585 | 1.227277 | 1.218321 |
| 3 | 1.220257 | 1.207999 | 1.221307 | 1.215932 |
| 4 | 1.213093 | 1.206606 | 1.219118 | 1.217127 |
| 5 | 1.217073 | 1.210585 | 1.224093 | 1.218520 |
| 6 | 1.217670 | 1.213967 | 1.208373 | 1.203390 |
| 7 | 1.203343 | 1.204219 | 1.203000 | 1.213145 |
| 8 | 1.213690 | 1.216155 | 1.224889 | 1.224692 |
| 9 | 1.227818 | 1.215558 | 1.216133 | 1.213742 |
| 10 | 1.214088 | 1.222521 | 1.221506 | 1.223099 |
| 11 | 1.222048 | 1.214564 | 1.229068 | 1.224094 |
| 12 | 1.220456 | 1.211978 | 1.216133 | 1.212747 |
| 13 | 1.211899 | 1.205413 | 1.204194 | 1.204187 |
| 14 | 1.212297 | 1.233065 | 1.217924 | 1.241613 |
| 15 | 1.234186 | 1.253754 | 1.245385 | 1.255548 |
| 16 | 1.253488 | 1.244205 | 1.253941 | 1.249576 |
| 17 | 1.249906 | 1.241619 | 1.240609 | 1.234247 |
| 18 | 1.230405 | 1.251367 | 1.241604 | 1.262516 |
| 19 | 1.265029 | 1.299708 | 1.274238 | 1.311090 |
| 20 | 1.309602 | 1.343871 | 1.320603 | 1.356679 |
| 21 | 1.355171 | 1.374706 | 1.366371 | 1.387535 |
| 22 | 1.385019 | 1.391217 | 1.391244 | 1.388531 |
| 23 | 1.389397 | 1.377491 | 1.375723 | 1.372008 |
| 24 | 1.371488 | 1.369533 | 1.373932 | 1.368822 |
| 25 | 1.367309 | 1.361775 | 1.375723 | 1.370017 |
| 26 | 1.369697 | 1.367146 | 1.379106 | 1.377781 |
| 27 | 1.376462 | 1.380475 | 1.384877 | 1.374197 |
| 28 | 1.376462 | 1.380475 | 1.384877 | 1.374197 |
| 29 | 1.376462 | 1.380475 | 1.384877 | 1.374197 |
| … | … | … | … | … |
| 838 | 1.389795 | 1.411906 | 1.400995 | 1.420980 |
| 839 | 1.419046 | 1.413498 | 1.427062 | 1.422971 |
| 840 | 1.422429 | 1.421455 | 1.433629 | 1.433323 |
| 841 | 1.431980 | 1.420858 | 1.427659 | 1.420781 |
| 842 | 1.421832 | 1.409519 | 1.410347 | 1.399679 |
| 843 | 1.397157 | 1.393406 | 1.405969 | 1.401670 |
| 844 | 1.399545 | 1.393207 | 1.400597 | 1.392910 |
| 845 | 1.393376 | 1.386045 | 1.404577 | 1.395299 |
| 846 | 1.395366 | 1.394400 | 1.406367 | 1.405253 |
| 847 | 1.404719 | 1.401363 | 1.402388 | 1.400873 |
| 848 | 1.400739 | 1.398976 | 1.402985 | 1.411823 |
| 849 | 1.411683 | 1.399374 | 1.411342 | 1.402267 |
| 850 | 1.401734 | 1.395793 | 1.410745 | 1.405651 |
| 851 | 1.405316 | 1.398777 | 1.415322 | 1.410031 |
| 852 | 1.414270 | 1.414691 | 1.425072 | 1.425559 |
| 853 | 1.426607 | 1.420262 | 1.420496 | 1.421975 |
| 854 | 1.421036 | 1.440951 | 1.432236 | 1.451638 |
| 855 | 1.451083 | 1.477754 | 1.462284 | 1.482494 |
| 856 | 1.478941 | 1.473377 | 1.474621 | 1.477916 |
| 857 | 1.476752 | 1.481135 | 1.487356 | 1.490059 |
| 858 | 1.490084 | 1.492873 | 1.497107 | 1.505786 |
| 859 | 1.506203 | 1.500233 | 1.495117 | 1.485879 |
| 860 | 1.489488 | 1.492873 | 1.499495 | 1.501805 |
| 861 | 1.501427 | 1.517341 | 1.503275 | 1.530273 |
| 862 | 1.535255 | 1.546386 | 1.531731 | 1.559338 |
| 863 | 1.559730 | 1.554343 | 1.565559 | 1.555754 |
| 864 | 1.558536 | 1.549569 | 1.551829 | 1.543013 |
| 865 | 1.542617 | 1.531068 | 1.541282 | 1.537638 |
| 866 | 1.534260 | 1.524304 | 1.522776 | 1.513152 |
| 867 | 1.511575 | 1.510578 | 1.512628 | 1.512953 |
868 rows × 4 columns In [24]:
#y_train as panda dataframe (optional, only for printing. See note in the beginning)
y_Train = pd.DataFrame(data=y_train)
y_Train.columns=["EURUSDclose"]
y_Train
Out[24]:
| EURUSDclose | |
|---|---|
| 0 | 1.04929 |
| 1 | 1.04868 |
| 2 | 1.04803 |
| 3 | 1.04782 |
| 4 | 1.04659 |
| 5 | 1.04668 |
| 6 | 1.04747 |
| 7 | 1.04699 |
| 8 | 1.04686 |
| 9 | 1.04655 |
| 10 | 1.04605 |
| 11 | 1.04592 |
| 12 | 1.04582 |
| 13 | 1.04525 |
| 14 | 1.04605 |
| 15 | 1.04573 |
| 16 | 1.04662 |
| 17 | 1.04763 |
| 18 | 1.04713 |
| 19 | 1.04838 |
| 20 | 1.04860 |
| 21 | 1.04814 |
| 22 | 1.04863 |
| 23 | 1.04586 |
| 24 | 1.04370 |
| 25 | 1.04100 |
| 26 | 1.03980 |
| 27 | 1.03931 |
| 28 | 1.03852 |
| 29 | 1.03910 |
| … | … |
| 7781 | 1.17498 |
| 7782 | 1.17761 |
| 7783 | 1.17852 |
| 7784 | 1.17861 |
| 7785 | 1.17945 |
| 7786 | 1.17985 |
| 7787 | 1.18191 |
| 7788 | 1.18186 |
| 7789 | 1.18222 |
| 7790 | 1.18178 |
| 7791 | 1.18139 |
| 7792 | 1.18139 |
| 7793 | 1.18229 |
| 7794 | 1.18214 |
| 7795 | 1.18324 |
| 7796 | 1.18343 |
| 7797 | 1.18288 |
| 7798 | 1.18280 |
| 7799 | 1.18299 |
| 7800 | 1.18425 |
| 7801 | 1.18431 |
| 7802 | 1.18404 |
| 7803 | 1.18463 |
| 7804 | 1.18429 |
| 7805 | 1.18489 |
| 7806 | 1.18466 |
| 7807 | 1.18460 |
| 7808 | 1.18496 |
| 7809 | 1.18490 |
| 7810 | 1.18488 |
7811 rows × 1 columns In [25]:
#y_train as panda dataframe (optional, only for printing. See note in the beginning)
y_Test = pd.DataFrame(data=y_test)
y_Test.columns=["EURUSDclose"]
y_Test
Out[25]:
| EURUSDclose | |
|---|---|
| 0 | 1.18514 |
| 1 | 1.18502 |
| 2 | 1.18490 |
| 3 | 1.18496 |
| 4 | 1.18503 |
| 5 | 1.18427 |
| 6 | 1.18476 |
| 7 | 1.18534 |
| 8 | 1.18479 |
| 9 | 1.18526 |
| 10 | 1.18531 |
| 11 | 1.18474 |
| 12 | 1.18431 |
| 13 | 1.18619 |
| 14 | 1.18689 |
| 15 | 1.18659 |
| 16 | 1.18582 |
| 17 | 1.18724 |
| 18 | 1.18968 |
| 19 | 1.19197 |
| 20 | 1.19352 |
| 21 | 1.19357 |
| 22 | 1.19274 |
| 23 | 1.19258 |
| 24 | 1.19264 |
| 25 | 1.19303 |
| 26 | 1.19285 |
| 27 | 1.19285 |
| 28 | 1.19285 |
| 29 | 1.19285 |
| … | … |
| 838 | 1.19530 |
| 839 | 1.19582 |
| 840 | 1.19519 |
| 841 | 1.19413 |
| 842 | 1.19423 |
| 843 | 1.19379 |
| 844 | 1.19391 |
| 845 | 1.19441 |
| 846 | 1.19419 |
| 847 | 1.19474 |
| 848 | 1.19426 |
| 849 | 1.19443 |
| 850 | 1.19465 |
| 851 | 1.19543 |
| 852 | 1.19525 |
| 853 | 1.19674 |
| 854 | 1.19829 |
| 855 | 1.19806 |
| 856 | 1.19867 |
| 857 | 1.19946 |
| 858 | 1.19846 |
| 859 | 1.19926 |
| 860 | 1.20069 |
| 861 | 1.20215 |
| 862 | 1.20197 |
| 863 | 1.20133 |
| 864 | 1.20106 |
| 865 | 1.19983 |
| 866 | 1.19982 |
| 867 | 1.19982 |
868 rows × 1 columns In [26]:
#y_train_std as panda dataframe (optional, only for printing. See note in the beginning)
y_Train_std = pd.DataFrame(data=y_train_std)
y_Train_std.columns=["EURUSDclose"]
y_Train_std
Out[26]:
| EURUSDclose | |
|---|---|
| 0 | -1.484129 |
| 1 | -1.496273 |
| 2 | -1.509213 |
| 3 | -1.513394 |
| 4 | -1.537881 |
| 5 | -1.536089 |
| 6 | -1.520362 |
| 7 | -1.529918 |
| 8 | -1.532506 |
| 9 | -1.538677 |
| 10 | -1.548632 |
| 11 | -1.551220 |
| 12 | -1.553211 |
| 13 | -1.564558 |
| 14 | -1.548632 |
| 15 | -1.555002 |
| 16 | -1.537284 |
| 17 | -1.517176 |
| 18 | -1.527131 |
| 19 | -1.502245 |
| 20 | -1.497865 |
| 21 | -1.507023 |
| 22 | -1.497268 |
| 23 | -1.552414 |
| 24 | -1.595416 |
| 25 | -1.649169 |
| 26 | -1.673059 |
| 27 | -1.682814 |
| 28 | -1.698541 |
| 29 | -1.686994 |
| … | … |
| 7781 | 1.018148 |
| 7782 | 1.070507 |
| 7783 | 1.088624 |
| 7784 | 1.090415 |
| 7785 | 1.107138 |
| 7786 | 1.115102 |
| 7787 | 1.156113 |
| 7788 | 1.155117 |
| 7789 | 1.162284 |
| 7790 | 1.153525 |
| 7791 | 1.145760 |
| 7792 | 1.145760 |
| 7793 | 1.163678 |
| 7794 | 1.160692 |
| 7795 | 1.182591 |
| 7796 | 1.186373 |
| 7797 | 1.175424 |
| 7798 | 1.173831 |
| 7799 | 1.177614 |
| 7800 | 1.202698 |
| 7801 | 1.203893 |
| 7802 | 1.198518 |
| 7803 | 1.210263 |
| 7804 | 1.203495 |
| 7805 | 1.215440 |
| 7806 | 1.210861 |
| 7807 | 1.209666 |
| 7808 | 1.216833 |
| 7809 | 1.215639 |
| 7810 | 1.215241 |
7811 rows × 1 columns In [27]:
#y_train_std as panda dataframe (optional, only for printing. See note in the beginning)
y_Test_std = pd.DataFrame(data=y_train_std)
y_Test_std.columns=["EURUSDclose"]
y_Test_std
Out[27]:
| EURUSDclose | |
|---|---|
| 0 | -1.484129 |
| 1 | -1.496273 |
| 2 | -1.509213 |
| 3 | -1.513394 |
| 4 | -1.537881 |
| 5 | -1.536089 |
| 6 | -1.520362 |
| 7 | -1.529918 |
| 8 | -1.532506 |
| 9 | -1.538677 |
| 10 | -1.548632 |
| 11 | -1.551220 |
| 12 | -1.553211 |
| 13 | -1.564558 |
| 14 | -1.548632 |
| 15 | -1.555002 |
| 16 | -1.537284 |
| 17 | -1.517176 |
| 18 | -1.527131 |
| 19 | -1.502245 |
| 20 | -1.497865 |
| 21 | -1.507023 |
| 22 | -1.497268 |
| 23 | -1.552414 |
| 24 | -1.595416 |
| 25 | -1.649169 |
| 26 | -1.673059 |
| 27 | -1.682814 |
| 28 | -1.698541 |
| 29 | -1.686994 |
| … | … |
| 7781 | 1.018148 |
| 7782 | 1.070507 |
| 7783 | 1.088624 |
| 7784 | 1.090415 |
| 7785 | 1.107138 |
| 7786 | 1.115102 |
| 7787 | 1.156113 |
| 7788 | 1.155117 |
| 7789 | 1.162284 |
| 7790 | 1.153525 |
| 7791 | 1.145760 |
| 7792 | 1.145760 |
| 7793 | 1.163678 |
| 7794 | 1.160692 |
| 7795 | 1.182591 |
| 7796 | 1.186373 |
| 7797 | 1.175424 |
| 7798 | 1.173831 |
| 7799 | 1.177614 |
| 7800 | 1.202698 |
| 7801 | 1.203893 |
| 7802 | 1.198518 |
| 7803 | 1.210263 |
| 7804 | 1.203495 |
| 7805 | 1.215440 |
| 7806 | 1.210861 |
| 7807 | 1.209666 |
| 7808 | 1.216833 |
| 7809 | 1.215639 |
| 7810 | 1.215241 |
7811 rows × 1 columns
Implement the model
In [28]:
# Clears the default graph stack and resets the global default graph
ops.reset_default_graph()
In [29]:
# make results reproducible
seed = 2
tf.set_random_seed(seed)
np.random.seed(seed)
# Parameters
learning_rate = 0.005
batch_size = 256
n_features = X_train.shape[1]# Number of features in training data
epochs = 1000
display_step = 100
model_path = model_dir+"07_First_Forex_Prediction"
production_model_path = production_dir+"models/"+"07_First_Forex_Prediction"
n_classes = 1
# Network Parameters
# See figure of the model
d0 = D = n_features # Layer 0 (Input layer number of features)
d1 = 1024 # Layer 1 (1024 hidden nodes)
d2 = 512 # Layer 2 (512 hidden nodes)
d3 = 256 # Layer 3 (256 hidden nodes)
d4 = 128 # Layer 4 (128 hidden nodes)
d5 = C = 1 # Layer 5 (Output layer)
# tf Graph input
print("Placeholders")
X = tf.placeholder(dtype=tf.float32, shape=[None, n_features], name="X")
y = tf.placeholder(dtype=tf.float32, shape=[None,n_classes], name="y")
# Initializers
print("Initializers")
sigma = 1
weight_initializer = tf.variance_scaling_initializer(mode="fan_avg", distribution="uniform", scale=sigma)
bias_initializer = tf.zeros_initializer()
# Create model
def multilayer_perceptron(X, variables):
# Hidden layer with ReLU activation
layer_1 = tf.nn.relu(tf.add(tf.matmul(X, variables['W1']), variables['bias1']), name="layer_1")
# Hidden layer with ReLU activation
layer_2 = tf.nn.relu(tf.add(tf.matmul(layer_1, variables['W2']), variables['bias2']), name="layer_2")
# Hidden layer with ReLU activation
layer_3 = tf.nn.relu(tf.add(tf.matmul(layer_2, variables['W3']), variables['bias3']), name="layer_3")
# Hidden layer with ReLU activation
layer_4 = tf.nn.relu(tf.add(tf.matmul(layer_3, variables['W4']), variables['bias4']), name="layer_4")
# Output layer with ReLU activation
out_layer = tf.nn.relu(tf.add(tf.matmul(layer_4, variables['W5']), variables['bias5']), name="out_layer")
return out_layer
# Store layers weight & bias
variables = {
'W1': tf.Variable(weight_initializer([n_features, d1]), name="W1"), # inputs -> d1 hidden neurons
'bias1': tf.Variable(bias_initializer([d1]), name="bias1"), # one biases for each d1 hidden neurons
'W2': tf.Variable(weight_initializer([d1, d2]), name="W2"), # d1 hidden inputs -> d2 hidden neurons
'bias2': tf.Variable(bias_initializer([d2]), name="bias2"), # one biases for each d2 hidden neurons
'W3': tf.Variable(weight_initializer([d2, d3]), name="W3"), ## d2 hidden inputs -> d3 hidden neurons
'bias3': tf.Variable(bias_initializer([d3]), name="bias3"), # one biases for each d3 hidden neurons
'W4': tf.Variable(weight_initializer([d3, d4]), name="W4"), ## d3 hidden inputs -> d4 hidden neurons
'bias4': tf.Variable(bias_initializer([d4]), name="bias4"), # one biases for each d4 hidden neurons
'W5': tf.Variable(weight_initializer([d4, d5]), name="W5"), # d4 hidden inputs -> 1 output
'bias5': tf.Variable(bias_initializer([d5]), name="bias5") # 1 bias for the output
}
# Construct model
y_hat = multilayer_perceptron(X, variables)
# Cost function
print("Cost function")
mse = tf.reduce_mean(tf.squared_difference(y_hat, y))
# Optimizer
print("Optimizer")
optimizer = tf.train.AdamOptimizer().minimize(mse)
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# 'Saver' op to save and restore all the variables
saver = tf.train.Saver()
def generate_one_epoch(X_train, y_train, batch_size):
num_batches = int(len(X_train)) // batch_size
if batch_size * num_batches < len(X_train):
num_batches += 1
batch_indices = range(num_batches)
batch_n = np.random.permutation(batch_indices)
for j in batch_n:
batch_X = X_train[j * batch_size: (j + 1) * batch_size]
batch_y = y_train[j * batch_size: (j + 1) * batch_size]
yield batch_X, batch_y
Placeholders Initializers Cost function Optimizer
Train the model and Evaluate the model
In [30]:
# Shape of tensors
print("X_train_std.shape = ", X_train_std.shape, "y_train.shape =", y_train.shape,
"\nX_train_std.shape = ", X_train_std.shape, "y_test.shape = ", y_test.shape)
X_train_std.shape = (7811, 4) y_train.shape = (7811,)
X_train_std.shape = (7811, 4) y_test.shape = (868,)
In [31]:
# Fit neural net
print("Fit neural net")
with tf.Session() as sess:
# Writer to record image, scalar, histogram and graph for display in tensorboard
writer = tf.summary.FileWriter("/tmp/tensorflow_logs", sess.graph) # create writer
writer.add_graph(sess.graph)
# Run the initializer
sess.run(init)
# Restore model weights from previously saved model
#Ram saver.restore(sess, model_path)
#Ram print("Model restored from file: %s" % model_path)
'''
# Try to restore a model if any.
try:
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
except Exception:
print("No model file to restore")
pass
'''
# Training cycle
mse_train = []
mse_test = []
# Run
print("Run")
printcounter = 0
for e in range(epochs):
# Minibatch training
for batch_X, batch_y in generate_one_epoch(X_train_std, y_train, batch_size):
# Run optimizer with batch
sess.run(optimizer, feed_dict={X: batch_X, y: np.transpose([batch_y])})
#Ram print("batch_X",batch_X)
#Ram print("batch_y",batch_y)
# Show progress
if (printcounter == display_step):
printcounter = 0
print("Epoch: ", e)
# MSE train and test
mse_train.append(sess.run(mse, feed_dict={X: X_train_std, y: np.transpose([y_train])}))
mse_test.append(sess.run(mse, feed_dict={X: X_test_std, y: np.transpose([y_test])}))
print('MSE Train: ', mse_train[-1])
print('MSE Test: ', mse_test[-1])
printcounter += 1
# Print final MSE after Training
mse_final = sess.run(mse, feed_dict={X: X_test, y: np.transpose([y_test])})
print(mse_final)
# Close writer
writer.flush()
writer.close()
# Save model weights to disk
save_path = saver.save(sess, model_path)
print("Model saved in file: %s" % save_path)
print("First Optimization Finished!")
Fit neural net Run Epoch: 100 MSE Train: 0.0066263936 MSE Test: 0.014807874 Epoch: 200 MSE Train: 0.0012716963 MSE Test: 1.1004695e-05 Epoch: 300 MSE Train: 0.011530105 MSE Test: 0.02958147 Epoch: 400 MSE Train: 0.06092236 MSE Test: 0.10722729 Epoch: 500 MSE Train: 0.00049403677 MSE Test: 0.00016906655 Epoch: 600 MSE Train: 0.010172739 MSE Test: 4.9944865e-05 Epoch: 700 MSE Train: 0.00041126224 MSE Test: 0.000107200845 Epoch: 800 MSE Train: 0.0005514498 MSE Test: 1.6022494e-05 Epoch: 900 MSE Train: 0.00016947073 MSE Test: 0.00035529005 4.568873e-05 Model saved in file: ../models/07_First_Forex_Prediction First Optimization Finished!
In [32]:
batch_y.shape
Out[32]:
(256,)
In [33]:
%matplotlib inline
# Plot loss (MSE) over time
plt.plot(mse_train, 'k-', label='mse_train')
plt.plot(mse_test, 'r--', label='mse_test')
plt.title('Loss (MSE) vs epoch')
plt.legend(loc='upper right')
plt.xlabel('Generation x'+str(display_step))
plt.ylabel('Loss')
plt.show()

Tensorboard Graph
What follows is the graph we have executed and all data about it. Note the “save” label and the several layers.

Saving a Tensorflow model
So, now we have our model saved.
Tensorflow model has four main files:
- a) Meta graph: This is a protocol buffer which saves the complete Tensorflow graph; i.e. all variables, operations, collections etc. This file has .meta extension.
- b) y c) Checkpoint files: It is a binary file which contains all the values of the weights, biases, gradients and all the other variables saved. Tensorflow has changed from version 0.11. Instead of a single .ckpt file, we have now two files: .index and .data file that contains our training variables.
- d) Along with this, Tensorflow also has a file named checkpoint which simply keeps a record of latest checkpoint files saved.
Predict
Finally, we can use the model to make some predictions. In [34]:
# Running a new session for predictions and export model to production
print("Starting prediction session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
# Try to restore a model if any.
try:
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# We try to predict the close price of test samples
feed_dict = {X: X_test_std}
prediction = sess.run(y_hat, feed_dict)
print(prediction)
%matplotlib inline
# Plot Prices over time
plt.plot(y_test, 'k-', label='y_test')
plt.plot(prediction, 'r--', label='prediction')
plt.title('Price over time')
plt.legend(loc='upper right')
plt.xlabel('Time')
plt.ylabel('Price')
plt.show()
if to_production:
# Pick out the model input and output
X_tensor = sess.graph.get_tensor_by_name("X"+ ':0')
y_tensor = sess.graph.get_tensor_by_name("out_layer" + ':0')
model_input = build_tensor_info(X_tensor)
model_output = build_tensor_info(y_tensor)
# Create a signature definition for tfserving
signature_definition = signature_def_utils.build_signature_def(
inputs={"X": model_input},
outputs={"out_layer": model_output},
method_name=signature_constants.PREDICT_METHOD_NAME)
model_version = 1
export_model_dir = production_model_path+"/"+str(model_version)
while os.path.exists(export_model_dir):
model_version += 1
export_model_dir = production_model_path+"/"+str(model_version)
builder = saved_model_builder.SavedModelBuilder(export_model_dir)
builder.add_meta_graph_and_variables(sess,
[tag_constants.SERVING],
signature_def_map={
signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature_definition})
# Save the model so we can serve it with a model server :)
builder.save()
except Exception:
print("Unexpected error:", sys.exc_info()[0])
pass
Starting prediction session... INFO:tensorflow:Restoring parameters from ../models/07_First_Forex_Prediction Model restored from file: ../models/07_First_Forex_Prediction [[1.1836615] [1.1830435] [1.1836624] [1.1831424] [1.1830487] . . .

INFO:tensorflow:No assets to save. INFO:tensorflow:No assets to write. INFO:tensorflow:SavedModel written to: b'/home/parrondo/PRODUCTION/models/07_First_Forex_Prediction/49/saved_model.pb'
In [35]:
dfvisual = pd.DataFrame()
dfvisual["y_test"] = y_test
dfvisual["prediction"]= prediction
dfvisual["Abs.error"]=dfvisual["y_test"]-dfvisual["prediction"]
dfvisual["Relat.error"]=abs(dfvisual["Abs.error"]/dfvisual["y_test"])*100
dfvisual
Out[35]:
| y_test | prediction | Abs.error | Relat.error | |
|---|---|---|---|---|
| 0 | 1.18514 | 1.183661 | 0.001479 | 0.124756 |
| 1 | 1.18502 | 1.183043 | 0.001977 | 0.166792 |
| 2 | 1.18490 | 1.183662 | 0.001238 | 0.104446 |
| 3 | 1.18496 | 1.183142 | 0.001818 | 0.153387 |
| 4 | 1.18503 | 1.183049 | 0.001981 | 0.167192 |
| 5 | 1.18427 | 1.183423 | 0.000847 | 0.071487 |
| 6 | 1.18476 | 1.182371 | 0.002389 | 0.201653 |
| 7 | 1.18534 | 1.181851 | 0.003489 | 0.294313 |
| 8 | 1.18479 | 1.183465 | 0.001325 | 0.111834 |
| 9 | 1.18526 | 1.182618 | 0.002642 | 0.222933 |
| 10 | 1.18531 | 1.183244 | 0.002066 | 0.174281 |
| 11 | 1.18474 | 1.183669 | 0.001071 | 0.090372 |
| 12 | 1.18431 | 1.182771 | 0.001539 | 0.129952 |
| 13 | 1.18619 | 1.182014 | 0.004176 | 0.352083 |
| 14 | 1.18689 | 1.182597 | 0.004293 | 0.361708 |
| 15 | 1.18659 | 1.184501 | 0.002089 | 0.176076 |
| 16 | 1.18582 | 1.184912 | 0.000908 | 0.076564 |
| 17 | 1.18724 | 1.184120 | 0.003120 | 0.262820 |
| 18 | 1.18968 | 1.184052 | 0.005628 | 0.473109 |
| 19 | 1.19197 | 1.185615 | 0.006355 | 0.533156 |
| 20 | 1.19352 | 1.188248 | 0.005272 | 0.441715 |
| 21 | 1.19357 | 1.191016 | 0.002554 | 0.213983 |
| 22 | 1.19274 | 1.192745 | -0.000005 | 0.000447 |
| 23 | 1.19258 | 1.191547 | 0.001033 | 0.086626 |
| 24 | 1.19264 | 1.191733 | 0.000907 | 0.076070 |
| 25 | 1.19303 | 1.191921 | 0.001109 | 0.092957 |
| 26 | 1.19285 | 1.192051 | 0.000799 | 0.066988 |
| 27 | 1.19285 | 1.192567 | 0.000283 | 0.023695 |
| 28 | 1.19285 | 1.192567 | 0.000283 | 0.023695 |
| 29 | 1.19285 | 1.192567 | 0.000283 | 0.023695 |
| … | … | … | … | … |
| 838 | 1.19530 | 1.193010 | 0.002290 | 0.191556 |
| 839 | 1.19582 | 1.194838 | 0.000982 | 0.082096 |
| 840 | 1.19519 | 1.195210 | -0.000020 | 0.001692 |
| 841 | 1.19413 | 1.194753 | -0.000623 | 0.052146 |
| 842 | 1.19423 | 1.193709 | 0.000521 | 0.043585 |
| 843 | 1.19379 | 1.193620 | 0.000170 | 0.014243 |
| 844 | 1.19391 | 1.193260 | 0.000650 | 0.054407 |
| 845 | 1.19441 | 1.193658 | 0.000752 | 0.062970 |
| 846 | 1.19419 | 1.193620 | 0.000570 | 0.047694 |
| 847 | 1.19474 | 1.193214 | 0.001526 | 0.127692 |
| 848 | 1.19426 | 1.193123 | 0.001137 | 0.095167 |
| 849 | 1.19443 | 1.193878 | 0.000552 | 0.046190 |
| 850 | 1.19465 | 1.193910 | 0.000740 | 0.061913 |
| 851 | 1.19543 | 1.194193 | 0.001237 | 0.103477 |
| 852 | 1.19525 | 1.194690 | 0.000560 | 0.046853 |
| 853 | 1.19674 | 1.194170 | 0.002570 | 0.214730 |
| 854 | 1.19829 | 1.194859 | 0.003431 | 0.286322 |
| 855 | 1.19806 | 1.196727 | 0.001333 | 0.111260 |
| 856 | 1.19867 | 1.197464 | 0.001206 | 0.100593 |
| 857 | 1.19946 | 1.198498 | 0.000962 | 0.080162 |
| 858 | 1.19846 | 1.199031 | -0.000571 | 0.047634 |
| 859 | 1.19926 | 1.199037 | 0.000223 | 0.018569 |
| 860 | 1.20069 | 1.199316 | 0.001374 | 0.114412 |
| 861 | 1.20215 | 1.199298 | 0.002852 | 0.237250 |
| 862 | 1.20197 | 1.201247 | 0.000723 | 0.060133 |
| 863 | 1.20133 | 1.204203 | -0.002873 | 0.239192 |
| 864 | 1.20106 | 1.203112 | -0.002052 | 0.170850 |
| 865 | 1.19983 | 1.202235 | -0.002405 | 0.200483 |
| 866 | 1.19982 | 1.200985 | -0.001165 | 0.097134 |
| 867 | 1.19982 | 1.200185 | -0.000365 | 0.030446 |
868 rows × 4 columns In [36]:
# Seaborn visualization library
import seaborn as sns
# Create the default pairplot
sns.pairplot(dfvisual)
Out[36]:
<seaborn.axisgrid.PairGrid at 0x7f109de84518>

OK, better results, but still not very good results. We could try to improve them with a deeper network (more layers) or retouching the net parameters and number of neurons. That is another story.
In [37]:
# Running a new session for predictions and export model to production
print("Starting prediction session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
# Try to restore a model if any.
try:
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# We try to predict the close price of test samples
X_test_pif = [[1.87374825, 1.87106024, 1.87083053, 1.86800846]]
feed_dict = {X: X_test_pif}
prediction = sess.run(y_hat, feed_dict)
print(prediction)
except Exception:
print("Unexpected error:", sys.exc_info()[0])
pass
Starting prediction session... INFO:tensorflow:Restoring parameters from ../models/07_First_Forex_Prediction Model restored from file: ../models/07_First_Forex_Prediction [[1.2461773]]
In [38]:
X_test_std
Out[38]:
array([[1.21508319, 1.21138084, 1.22528685, 1.21553408],
[1.218267 , 1.20799896, 1.22110807, 1.22071004],
[1.2198589 , 1.2105851 , 1.22727675, 1.21832114],
...,
[1.5426173 , 1.53106792, 1.54128243, 1.53763841],
[1.53425981, 1.52430416, 1.52277639, 1.51315211],
[1.51157518, 1.51057771, 1.51262792, 1.51295304]])In [39]:
# Running a new session for predictions and export model to production
print("Starting prediction session...")
with tf.Session() as sess:
# Initialize variables
sess.run(init)
saver.restore(sess, model_path)
print("Model restored from file: %s" % model_path)
# We try to predict the close price of test samples
feed_dict = {X: X_test_std}
prediction = sess.run(y_hat, feed_dict)
print(prediction)
%matplotlib inline
# Plot Prices over time
plt.plot(y_test, 'k-', label='y_test')
plt.plot(prediction, 'r--', label='prediction')
plt.title('Price over time')
plt.legend(loc='upper right')
plt.xlabel('Time')
plt.ylabel('Price')
plt.show()
# Pick out the model input and output
X_tensor = sess.graph.get_tensor_by_name("X"+ ':0')
y_tensor = sess.graph.get_tensor_by_name("out_layer" + ':0')
model_input = build_tensor_info(X_tensor)
model_output = build_tensor_info(y_tensor)
# Create a signature definition for tfserving
signature_definition = signature_def_utils.build_signature_def(
inputs={"X": model_input},
outputs={"out_layer": model_output},
method_name=signature_constants.PREDICT_METHOD_NAME)
model_version = 1
export_model_dir = production_model_path+"/"+str(model_version)
while os.path.exists(export_model_dir):
model_version += 1
export_model_dir = production_model_path+"/"+str(model_version)
builder = saved_model_builder.SavedModelBuilder(export_model_dir)
builder.add_meta_graph_and_variables(sess,
[tag_constants.SERVING],
signature_def_map={
signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
signature_definition})
# Save the model so we can serve it with a model server :)
builder.save()
Starting prediction session...
INFO:tensorflow:Restoring parameters from ../models/07_First_Forex_Prediction
Model restored from file: ../models/07_First_Forex_Prediction
[[1.1836615]
[1.1830435]
[1.1836624]
[1.1831424]
[1.1830487]
[1.1834234]
[1.1823709]
.
.
.
INFO:tensorflow:No assets to save. INFO:tensorflow:No assets to write. INFO:tensorflow:SavedModel written to: b'/home/parrondo/PRODUCTION/models/07_First_Forex_Prediction/50/saved_model.pb'
In [40]:
len(y_train)
Out[40]:
7811
In [41]:
X_Train_std
Out[41]:
| EURUSDopen | EURUSDhigh | EURUSDlow | EURUSDclose | |
|---|---|---|---|---|
| 0 | -1.438023 | -1.438023 | -1.431822 | -1.439736 |
| 1 | -1.438620 | -1.445583 | -1.471819 | -1.483732 |
| 2 | -1.490953 | -1.499494 | -1.504453 | -1.495876 |
| 3 | -1.495530 | -1.503274 | -1.499280 | -1.508816 |
| 4 | -1.507668 | -1.517796 | -1.503856 | -1.512996 |
| 5 | -1.512245 | -1.523764 | -1.526740 | -1.537483 |
| 6 | -1.537517 | -1.544055 | -1.534302 | -1.535691 |
| 7 | -1.537517 | -1.530727 | -1.527536 | -1.519964 |
| 8 | -1.524980 | -1.534307 | -1.529924 | -1.529519 |
| 9 | -1.529358 | -1.525952 | -1.522163 | -1.532107 |
| 10 | -1.530552 | -1.542066 | -1.533108 | -1.538279 |
| 11 | -1.537716 | -1.547039 | -1.536292 | -1.548233 |
| 12 | -1.548461 | -1.554599 | -1.541067 | -1.550821 |
| 13 | -1.550650 | -1.560567 | -1.544251 | -1.552811 |
| 14 | -1.552043 | -1.563551 | -1.557981 | -1.564159 |
| 15 | -1.561594 | -1.539679 | -1.550818 | -1.548233 |
| 16 | -1.545277 | -1.544453 | -1.545843 | -1.554603 |
| 17 | -1.554033 | -1.539480 | -1.542858 | -1.536885 |
| 18 | -1.536522 | -1.519188 | -1.525546 | -1.516779 |
| 19 | -1.517021 | -1.525753 | -1.515199 | -1.526732 |
| 20 | -1.525179 | -1.512624 | -1.514403 | -1.501848 |
| 21 | -1.499709 | -1.501085 | -1.492713 | -1.497468 |
| 22 | -1.492346 | -1.501085 | -1.494703 | -1.506626 |
| 23 | -1.504684 | -1.503871 | -1.493509 | -1.496871 |
| 24 | -1.492744 | -1.504268 | -1.549425 | -1.552015 |
| 25 | -1.548461 | -1.551814 | -1.613301 | -1.595015 |
| 26 | -1.598009 | -1.608709 | -1.651706 | -1.648766 |
| 27 | -1.664471 | -1.647899 | -1.662252 | -1.672655 |
| 28 | -1.675017 | -1.684105 | -1.692101 | -1.682410 |
| 29 | -1.679594 | -1.691067 | -1.705831 | -1.698137 |
| … | … | … | … | … |
| 7781 | 1.024055 | 1.011850 | 1.006000 | 1.001130 |
| 7782 | 1.002962 | 1.014237 | 1.013363 | 1.018449 |
| 7783 | 1.019677 | 1.060788 | 1.030874 | 1.070806 |
| 7784 | 1.069822 | 1.097988 | 1.073458 | 1.088922 |
| 7785 | 1.090119 | 1.100575 | 1.096143 | 1.090714 |
| 7786 | 1.095292 | 1.100972 | 1.102311 | 1.107436 |
| 7787 | 1.108426 | 1.102962 | 1.115047 | 1.115399 |
| 7788 | 1.115191 | 1.155679 | 1.121016 | 1.156409 |
| 7789 | 1.167724 | 1.155480 | 1.157431 | 1.155413 |
| 7790 | 1.157576 | 1.154287 | 1.166386 | 1.162580 |
| 7791 | 1.158770 | 1.147921 | 1.162207 | 1.153821 |
| 7792 | 1.153596 | 1.146528 | 1.156834 | 1.146057 |
| 7793 | 1.147029 | 1.145932 | 1.156834 | 1.146057 |
| 7794 | 1.146233 | 1.153889 | 1.157431 | 1.163973 |
| 7795 | 1.163346 | 1.154685 | 1.164595 | 1.160987 |
| 7796 | 1.159168 | 1.180546 | 1.167580 | 1.182886 |
| 7797 | 1.182051 | 1.179750 | 1.193250 | 1.186668 |
| 7798 | 1.186827 | 1.179750 | 1.180315 | 1.175719 |
| 7799 | 1.176480 | 1.174578 | 1.182902 | 1.174126 |
| 7800 | 1.173893 | 1.181541 | 1.178723 | 1.177909 |
| 7801 | 1.170311 | 1.194670 | 1.181509 | 1.202992 |
| 7802 | 1.206328 | 1.198251 | 1.201806 | 1.204187 |
| 7803 | 1.202348 | 1.194074 | 1.205388 | 1.198812 |
| 7804 | 1.210506 | 1.207203 | 1.213347 | 1.210557 |
| 7805 | 1.208318 | 1.210983 | 1.210761 | 1.203789 |
| 7806 | 1.203940 | 1.203026 | 1.214740 | 1.215733 |
| 7807 | 1.215879 | 1.208994 | 1.220710 | 1.211154 |
| 7808 | 1.208915 | 1.211978 | 1.218919 | 1.209960 |
| 7809 | 1.203542 | 1.204617 | 1.209169 | 1.217127 |
| 7810 | 1.218665 | 1.212972 | 1.223496 | 1.215932 |
7811 rows × 4 columns In [42]:
y_train.shape
Out[42]:
(7811,)
In [43]:
# Mean relative error
dfvisual["Relat.error"].mean()
Out[43]:
0.15334987531611016In [44]:
# Mean Absolute error
dfvisual["Abs.error"].mean()
Out[44]:
0.0017724057803175793Incredible just 18 pips of absolute error!
In the next







16 COMMENTS
[…] DeepTrading with TensorFlow VI [Todo Trader] […]
Hello, I have read all your articles on the blog more than one time. I enjoyed them a lot, and I am very glad I have discovered your blog.
Thank you very much for the content about Deep Learning applied to trading with Tensorflow as there are not any resources available to learn that. I will continue following you. Thank you so much for sharing this content. Keep up the good work!
Hello,
I am very interested in the whole series and learning to apply Deep Learning to trading.
I have a number of questions that I hope you will be able to give me some answers to:
1) As I am trying to replicate the results but I am encountering a problem:
When I go and try to train the model, the code snippet I get for the “MSE Test” is nan for all the epochs. Why is that, do you know?
2) I have not understood properly how to create the environment and save the results of the model in a directory so that I can re-access the model in the future. I am running the code into Jupyter Lab after downloading your github; I am working on a sheet opened into the directory ‘eurusd’ since I am not working with any database.
I hope you might help.
3) Do you know any comprehensive solution to learn Deep Learning specifically applied to trading?
Thank you very much.
Kind regards.
Hi Nick,
Thanks for your kind words. In these moments I am finishing the next post that I will publish shortly. I hope you like it and all the readers.
1) The results are reproducible. You must set up your environment properly using Conda (Anaconda or Miniconda). I cannot help you with your MSE Test NAN with this info. About reproducibility remember my post:
https://todotrader.com/quant-trading-project-structure/
And, try what follows in answer 2)
2) What I recommend is “conda env create –file environment.yml”. You must install Anaconda or Miniconda: https://docs.conda.io/projects/conda/en/latest/user-guide/getting-started.html
If you are not familiar with Anaconda then try to Google any good tutorial.
3) There is not a comprehensive solution to learn Deep Learning for trading, it is a big task and it is one of the targets of this blog.
Little by little I will introduce everything I have learned for years. The objective will be for any trader to be able to start and place their first order in the market using open source solutions wherever possible. All this using the latest techniques for creating trading systems.
But there are great resources to learn Machine Learning for trading:
I recommend you to start theory reading:
”Advances in Financial Machine Learning” Marcos López de Prado (2018)
“Machine Trading: Deploying Computer Algorithms to Conquer the Markets” (Wiley Trading) Ernest P. Chan (2017)
Also, you can get good Machine Learning Lessons on the site: https://machinelearningmastery.com/ but it is not specific for trading.
Hello, parrondo.
I am already using Anaconda but I am not using Linux. How can I replicate your environment creation procedure with my setup?(Also I am used to using the command line very much so if that is needed, please I would be very grateful if you could explain step by step the process of setting up the environment in anaconda Windows).
Thank you so much for your comment and recommendation.
I will continue following your posts very actively!
Thanks.
Nick
I am writing detailed instructions that will be in the DeepTrading GitHub repository. I hope it will help you.
Hi parrondo,
Thank you very much for the support!
I just uploaded more detailed instructions to my Github repo in order to follow all posts about DeepTrading with Tensorflow.
https://github.com/parrondo/deeptrading
Again, Thank you very much for the support!!
Hola,
I have reviewed quickly the post and first doubt caming into my mind is:
Why in this case for optimization you have used “AdamOptimizer” (optimizer = tf.train.AdamOptimizer().minimize) instead of the one used in the previous post: GradientDescentOptimizer (optimizer = tf.train.GradientDescentOptimizer().minimize)??
Gracias otra vez por este gran blog.
Saludos.
Hola,
Yes you are right, it is because I test several combinations before posting, and then select what seems better, but sometimes, there are no great differences. And this is the case, so it does not matter which one to use. This kind of details will be very relevant when we use big networks or big data.
De nada,
Saludos
Hola otra vez,
una duda conceptual.
Why to include the “close price” in the features? I was thinking, ok, with the 3 input values we should be able to predict the 4th one, but not to use it as well as input at the begining.
Would it work removing it from the features (adapting the code, of course)?
It is something I plan test once I have fully undertood the full code.
Anyway, if you have a theorical reason for that it will help me to avoid mistakes in my future models 🙂
Gracias.
Saludos.
Hi JLG,
I include the four “OHLC” data at the time “t” in order to calculate “C” at time “t+1”. But it is just an exercise. To be rigorous we should test the features we want to use again results.
Caution! you are approaching the problem of how to Identify the Most Important Independent Variables and determining which variable is the most relevant usually is more complicated than it first appears. There are a full variety of techniques which trying to answer this question. For example, some techniques calculate how R-squared increases when we add each variable to a model that already contains all of the other variables. R-squared is the percentage of the response variable variation that is explained by a “linear model.” So if you have time you could test to identify the independent variable that produces the largest R-squared increase when it is the last variable added to the model. That is, you can calculate the sensibility of the model to the feature “Close Price”. It is not trivial.
Por cierto,
I have copied the code and executed it in different days, and althought graph is similar, my “mean_relative_error” and “absolute_error” of the last prediction are different (0.06316668866630704 and -0.00029683744531624405 respectively).
Is it normal or I did anything wrong and results should match exactly with the ones in this page?
(No se como adjuntar el grafico)
Saludos.
Well, unfortunately, it is more frequent than we would like. There are some explanations there. We are using Jupyter Notebook, with the possibility to execute the code several times. Here we can be making calculations with the same session of Tensorflow. Caution with this last. See post: http://ronny.rest/blog/post_2017_09_11_tf_metrics/