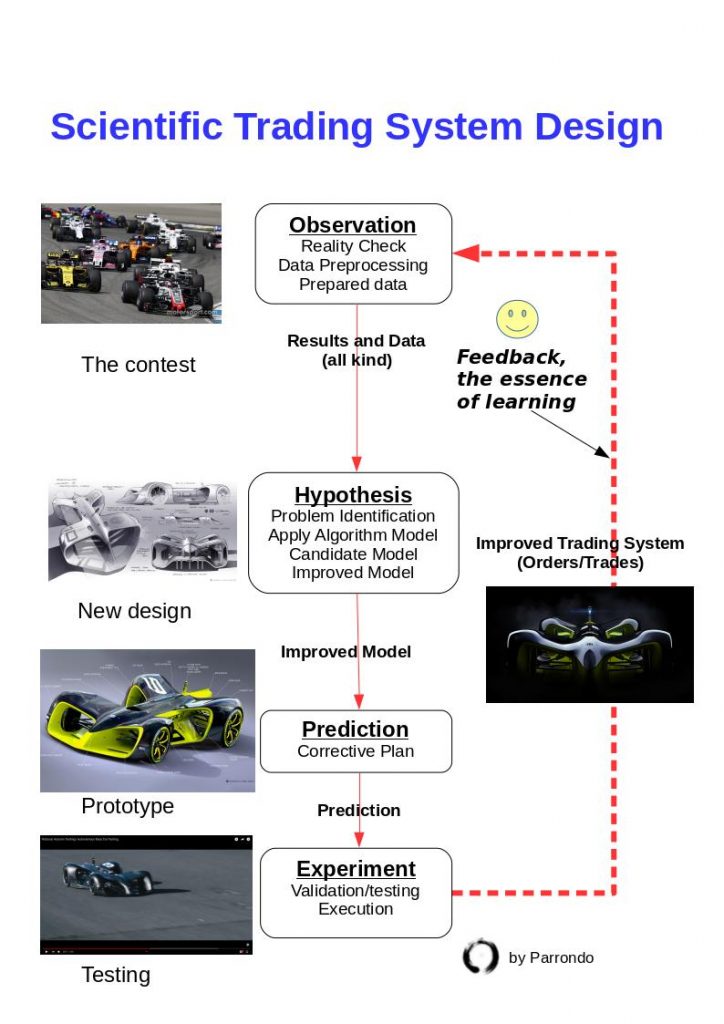
Be Productive
Be Productive Quant Trading Project Structure
The Quant Trading Project Structure is a logical and reasonably simple project structure for developing quantitative trading work like strategies and research works.
Why use this simple project structure?
When we think about quantitative trading research, we often think just about the resulting strategies, reports, or graph visualizations. While these final products are generally the main objects, it’s easy to focus on making the products look nice and convincing to the third party, even for yourself and forgetting the quality of the code that generates them. Trading research science code quality is about correctness, standardization, and reproducibility.
It is not a secret that good analysis is often the result of very scattered and random explorations. Tentative experiments and rapid testing approaches that may not work are part of the process to get good trading strategies.
Having said that, once it is started, it is not a process that lends itself to thinking carefully about the structure of your code or project design, so it is best to start with a logical and clean structure and stick to it at all times.
If you ever tried to reproduce an analysis you or your team did a few months ago or even a few years ago you know what I mean. You may have written the code, but now it is impossible to decrypt whether you should use first_test.py, first_test_01.py or new_first_test.py to get things done.
Welcome to Quant Trading Project Structure!
Below we expose a simple project structure for quantitative traders who want to develop new strategies or make research and development works. It is based in the following works and we use either of them, depending on the work
luigi_data_science_project_cookiecutter
Index
- Reproducibility is the name of the game
- You will get what you put: Provenance
- Getting started
- Default folder structure quasi-immutability
- Final Notes
- References
Reproducibility is the name of the game
There are two basic reasons to make your research reproducible. The first is to show evidence of the correctness of your results. The second one is to enable others to make use of our methods and results. So to achieve it we need to recognize that:
- A well-defined standard project structure means that a newcomer can begin to understand an analysis without having to look into an extensive documentation.
- It also means that you do not necessarily have to read 100% of the code before you know where to look for very specific things.
- A well-organized code tends to self-document, since the organization itself provides the context for its code without too much overhead.
- Your team collaborates more easily with you on this analysis
- Learn yourself from your analysis about the research process
- Feel more confident in the conclusions of the project
You will get out what you put in: Provenance
The term “data provenance” refers to a record that explains the origin of a piece of data (in a database, document or repository) along with an explanation of how and why it arrived at the current location. Trading quants need the provenance like the trees the sunlight.
Example: In an application like quantitative strategies, a lot of data is derived from public databases or brokers, which in turn might be derived from papers but after some clearing and transformations (only the most significant data are put into the public database), which are derived from data markets. A good provenance record will keep the whole history for each piece of data. Here are some questions we have learned to ask with a sense of existential fear:
- Are we supposed to go in and join the feature column X to the data before we get started (raw data) or did that come from one of our notebooks?
- Come to think of it, which notebook do we have to run first before running the plotting code: was it “process data” or “clean data”?
- Where did the shapefiles get downloaded from for the price plots?
Etceter a, etcetera, …
These types of questions are painful and are symptoms of a disorganized, foolish project. A good project structure encourages practices that make it easier to come back to old work. You should make sure that it is clear on how you came to certain conclusions. Just because something makes sense to you, it is not clear that it does for others (yourself next month). When making claims based on your analysis, you must link them to the data on which you base them. This is to ensure that you or others who read your work can easily follow the steps you took from the data to the conclusions. Having a complete context makes it easy to understand the work process and relate to it by reproducing it.
Another benefit is that all raw data remains available to you and, if you wish, for others, to access and consult. This helps transparency and, again, makes it easier for others to understand your workflow.
Getting started
We’ve created a data science like bash script for Linux to start the template for projects in Python. This script contains the three above template types. Your analysis doesn’t have to be in Python, but the templates do provide some Python boilerplates.
Requirements
- Python 2.7 or 3.5
- cookiecutter Python package >= 1.4.0: pip install cookiecutter
- Linux OS (We use Centos 7 but whatever you want will do the job)
name: sphinx
dependencies:
- python=3.5 # or 2.7
- pip:
- sphinx==1.5.6
- Flask-Sphinx-Themes *(optional, is only an example!)*
- recommonmark
and execute:
$ conda env create --file environment.yml $ source activate sphinx
The Script
In the new_project.sh script there are simple instructions to start a new project from scratch.
#!/bin/bash
#2018, Parrondo https://github.com/parrondo/quant-trading-project-structure
#Starting a new project is as easy as running this command at the command line. No need to create a directory first,
#the cookiecutter will do it for you.
#Conda python environment activation where cookiecutter lives.
source activate cookiecutter
echo -e "What kind of new project do you want? \nData-Science [ds] \nDeepLearning [dl] \nData-Science-Luigi [lu] \nSphinx [sp]: "
read answer
case $answer in
ds|Ds|dS|DS)
echo "Agreed, you want a Data-Science new project"
#Creating files and project folder structure with cookiecutter-data-science
cookiecutter https://github.com/drivendata/cookiecutter-data-science
;;
dl|Dl|dL|DL)
echo echo "Agreed, you want a DeepLearning new project"
#Creating files and project folder structure with cookiecutter-deeplearning
cookiecutter https://github.com/tdeboissiere/cookiecutter-deeplearning.git
;;
lu|Lu|lU|LU)
echo "Agreed, you want a Data-Science with Luigi new project"
cookiecutter https://github.com/ffmmjj/luigi_data_science_project_cookiecutter
;;
sp|Sp|sP|SP)
echo "Agreed, you want a Sphinx documentation new project"
cookiecutter https://github.com/carschar/cookiecutter-sphinx.git
;;
*) echo "Invalid input"
;;
esac
Starting a new project
Starting a new project is as easy as running this command at the command line. No need to create a directory first, the cookiecutter you select in the dialog will do it for you. Remember to change the file new_project.sh as an executable file, also you’ll place the file into the parent folder of the new project structure. Then, execute:
$ ./new_project.sh
this command will create my_project structure (see example below)
Example of Directory structure (Data Science type project)
After finishing setup, some build folders should be ignored during git commit. By default, these folders are as follow:
The resulting directory structure
The directory structure of your new project looks like this:
my_project │ ├── LICENSE ├── Makefile <- Makefile with commands like `make data` or `make train` ├── README.md <- The top-level README for developers using this project. ├── data │ ├── external <- Data from third party sources. │ ├── interim <- Intermediate data that has been transformed. │ ├── processed <- The final, canonical data sets for modeling. │ └── raw <- The original, immutable data dump. │ ├── docs <- A default Sphinx project; see sphinx-doc.org for details │ ├── models <- Trained and serialized models, model predictions, or model summaries │ ├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering), │ the creator's initials, and a short `-` delimited description, e.g. │ `1.0-jqp-initial-data-exploration`. │ ├── references <- Data dictionaries, manuals, and all other explanatory materials. │ ├── reports <- Generated analysis as HTML, PDF, LaTeX, etc. │ └── figures <- Generated graphics and figures to be used in reporting │ ├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g. │ generated with `pip freeze > requirements.txt` │ ├── src <- Source code for use in this project. │ ├── __init__.py <- Makes src a Python module │ │ │ ├── data <- Scripts to download or generate data │ │ └── make_dataset.py │ │ │ ├── features <- Scripts to turn raw data into features for modeling │ │ └── build_features.py │ │ │ ├── models <- Scripts to train models and then use trained models to make │ │ │ predictions │ │ ├── predict_model.py │ │ └── train_model.py │ │ │ └── visualization <- Scripts to create exploratory and results oriented visualizations │ └── visualize.py │ └── tox.ini <- tox file with settings for running tox; see tox.testrun.org
Data is immutable
- Most important: don’t ever edit your carefully and usually expensive downloaded raw data, especially not manually, and especially not in Excel or whatever worksheet.
- Don’t overwrite your raw data ever.
- Don’t save multiple versions of the raw data.
- Treat the data (and its format) as immutable.
- The code you write should move the raw data through a pipeline to your final analysis (Luigi is perfect for this task).
- You shouldn’t have to run all of the steps every time you want to make a new figure, but anyone should be able to reproduce the final products with only the code in src and the data in data/raw.
Also, if data is immutable, it doesn’t need source control in the same way that code does. Therefore, by default, the data folder is included in the .gitignore file. If you have a small amount of data that rarely changes, you may want to include the data in the repository. Github currently warns if files are over 50MB and it reject files over 100MB.
Notebooks are for exploration and communication
Notebook packages like the Jupyter notebook, are very effective for exploratory data analysis. However, these tools can be less effective for reproducing an analysis. When we use notebooks in our work, we identify the notebooks files. For example, 01-ram-exploratory.
There are two steps we recommend for using notebooks effectively:
- Follow a naming convention that shows the owner and the order the analysis was done in. We use the format: <step>-<user>-<description>.ipynb (e.g., “01-ram-data-preparation.ipynb”, “03-ram-returns-visualization.ipynb”).
- Refactor the good parts. Don’t write code to do the same task in multiple notebooks. If it’s a data preprocessing task, put it in the pipeline at src/data/make_dataset.py and load data from data/interim.
Build from a Conda environment
The first step in reproducing an analysis is always reproducing the computational environment it was run in. You need the same tools, the same libraries, and the same versions to make everything play nicely together. One effective approach to this is by using Anaconda. By listing all of your requirements in the repository (it is include a requirements.txt file) you can easily track the packages needed to recreate the analysis. Here is an example of a
1. Create an environment.yml file in the project folder. Typically the environment name, ENV_NAME, will be the same as the folder name. At minimum, it will specify the version of Python you want to use. 2. $ conda env create. 3. $ source activate ENV_NAME (to activate the environtment) 4. (myenv)$ pip install the packages that your analysis needs 5. Run pip freeze > requirements.txt (to pin the exact package versions used to recreate the analysis). Update environment.yml with requirements.txt (delete requirements.txt). 6. If you find you need to install another package: run pip freeze > requirements.txt again, update environment.yml with requirements.txt (delete requirements.txt), and commit the changes to version control.
Usually, you have more complex requirements for recreating your environment, therefore you should consider a virtual machine based approach such as Docker or Vagrant. Both of these tools use text-based formats (Dockerfile and Vagrantfile respectively) and consequently you can easily add to source control to describe how to create a virtual machine with the requirements you need. Once you are familiarized with this virtual machine techniques, they work like a charm.
If you need orchestration then use, for example, Kubernetes, Mesos, and Docker Swarm. These last ones are more for production scale and so, out of the scope of this post.
Secrets and configuration should be kept out of version control
You really don’t want to leak your username and password on Github. Here’s how to do this:
Store your secrets and config variables in a special file
Create a .env file in the project root folder. Thanks to the .gitignore, this file should never get committed into the version control repository. Here’s an example:
# example .env file DATABASE_URL=mongodb://username:password@localhost:5432/dbname AWS_ACCESS_KEY=myaccesskey AWS_SECRET_ACCESS_KEY=mysecretkey OTHER_VARIABLE=something
Use a package to load these variables automatically
If you look at the stub script in src/data/make_dataset.py, it uses a package called python-dotenv to load up all the entries in this file as environment variables so they are accessible with os.environ.get. Here’s an example snippet adapted from the python-dotenv documentation:
# src/data/dotenv_example.py
import os
from dotenv import load_dotenv, find_dotenv
# find .env automagically by walking up directories until it's found
dotenv_path = find_dotenv()
# load up the entries as environment variables
load_dotenv(dotenv_path)
database_url = os.environ.get("DATABASE_URL")
other_variable = os.environ.get("OTHER_VARIABLE")
Default folder structure quasi-immutability
if you want to keep this structure broadly applicable to many different kinds of projects, then, the
Now you have a folder-layout label specifically for your trading development works to add, subtract, rename, or move folders around.
Be careful and be consistent!
Don’t forget to clone or download the script from here: quant-trading-project-structure
Be careful and be consistent!
Final notes
This post is an actualization of my Github work:
https://parrondo.github.io/quant-trading-project-structure/
Don’t forget to clone or download the script from here: quant-trading-project-structure
References
- GitHub. (2019). drivendata/cookiecutter-data-science. [online] Available at: https://github.com/drivendata/cookiecutter-data-science [Accessed 25 May 2019].
- GitHub. (2017). ffmmjj/luigi_data_science_project_cookiecutter. [online] Available at: https://github.com/ffmmjj/luigi_data_science_project_cookiecutter [Accessed 23 Oct. 2017].
- GitHub. (2017). tdeboissiere/cookiecutter-deeplearning. [online] Available at: https://github.com/tdeboissiere/cookiecutter-deeplearning [Accessed 23 Oct. 2017]. Ropensci.github.io. (2017).
- Reproducibility Guide. [online] Available at: http://ropensci.github.io/reproducibility-guide/sections/introduction/ [Accessed 23 Oct. 2017]. Conda.io. (2017).
- Conda — Conda documentation. [online] Available at: https://conda.io/docs/index.html [Accessed 25 May 2019].
- GitHub. (2017). theskumar/python-dotenv. [online] Available at: https://github.com/theskumar/python-dotenv [Accessed 25 May 2019].